What Is Reverse Engineering in Software Engineering?
Reverse engineering in software engineering refers to the analysis of existing software to understand its structure, operation, and functionality, often when source code or adequate documentation is unavailable. This process involves deconstructing software applications into their components or code blocks, enabling engineers to discern how features work, dependencies are managed, and which technologies are in use. The primary aim is to recover lost information, adapt software for new uses, or analyze functionality for debugging and improvement.
While reverse engineering is often associated with code disassembly, it also includes processes like protocol analysis, data structure discovery, and behavior examination at runtime. Whether the goal is to support legacy systems, expose vulnerabilities, or enable interoperability with newer components, reverse engineering is a key skill in modern software maintenance, cybersecurity, and system integration. It serves as a bridge between unknown, undocumented implementations and the need for clarity, control, or transformation of software artifacts.
This is part of a series of articles about mainframe modernization
Primary Goals of Reverse Engineering
Legacy System Migration
Legacy system migration is a leading driver for software reverse engineering. Many organizations rely on business-critical software developed in outdated languages or frameworks, lacking documentation and maintenance support. Through reverse engineering, technical teams extract functional and architectural knowledge from these systems, enabling modernization or migration to contemporary platforms. This step is vital for ensuring continuity of business logic while embracing newer, more secure, and scalable technologies.
Reverse engineering aids in minimizing business disruption during migration. By understanding legacy system dependencies, data flow, and integration points, teams can mitigate risks associated with code refactoring or re-platforming. The resulting documentation and models act as blueprints for phased transitions, efficient testing, and accurate replication of functionality in the target environment.
Malware Analysis and Cybersecurity
Reverse engineering is fundamental to malware analysis and broader cybersecurity efforts. Security researchers dissect malicious binaries, scripts, or network payloads to determine their behavior, infection vectors, and exploit mechanisms. By reconstructing the malware’s control flow and code logic, analysts identify indicators of compromise (IoCs), hidden payloads, and techniques used to evade detection, enabling the development of responses, detection signatures, and remediation strategies.
This process not only enables incident response but also enhances defensive measures over time. Continuous reverse engineering of new and evolving threats provides insights into adversarial tactics, techniques, and procedures (TTPs). It empowers security teams to anticipate similar attacks and deploy proactive security controls.
Interoperability Between Components
Ensuring communication between diverse software components is a frequent application of reverse engineering. When proprietary or undocumented systems must interact within a heterogeneous environment, engineers analyze protocols, data formats, and application programming interfaces (APIs) to build adapters or bridges. This is particularly relevant for integrating third-party services, legacy databases, or closed-format tools with new platforms or microservice-based architectures.
Reverse engineering for interoperability saves time by avoiding complete system rewrites and builds flexibility into evolving technology stacks. Teams can validate assumptions about how information is transmitted or stored and replicate or extend interfaces as needed. These integrations enable businesses to extract value from legacy investments while transitioning to agile and interoperable software ecosystems.
Software Quality Enhancement
Reverse engineering promotes software quality improvement by revealing architectural flaws, redundant code, or hidden dependencies. By fully understanding how software operates internally, teams can identify areas prone to defects, inadequate error handling, or performance bottlenecks. Through thorough analysis, issues that might have gone undetected in superficial code reviews—such as race conditions or memory leaks—are brought to light for remediation.
Applying reverse engineering for quality enhancement also aids in optimizing codebase maintainability. Teams gain insights into code reusability, potential for modularization, and adherence to design principles. This knowledge supports better testing, targeted refactoring, and the introduction of automation tools, leading to more stable, robust, and future-proof software products.
Related content: Read our guide to mainframe migration
The Reverse Engineering Process
Here are the typical steps undertaken in a reverse engineering process:
1. Prescreening
Prescreening marks the initial phase in reverse engineering, where practitioners assess the software artifact’s feasibility for deeper analysis. This phase involves gathering high-level information such as the executable’s platform, file format, dependencies, and size. The goal is to quickly rule out artifacts that are encrypted, obfuscated beyond current capability, or otherwise inaccessible, allowing the reverse engineer to allocate resources efficiently.
Additionally, prescreening checks for the presence of anti-tamper techniques, such as packers or digital signatures, which could hinder subsequent analysis. Recognizing these obstacles at an early stage informs both the choice of tools and the refinement of the engineering approach. A thorough prescreening process prevents wasted effort and establishes the groundwork for a simplified reverse engineering workflow.
2. Information Gathering
Information gathering is a systematic effort to collect external data about the software under investigation. Engineers review any available documentation, release notes, and help files, supplementing gaps by examining UI elements, runtime logs, or observed network traffic. This contextual knowledge can shed light on feature sets, expected system inputs and outputs, and architectural decisions that guide deeper scrutiny.
During this phase, analysts often collect environmental information, such as required libraries, configuration files, or environmental variables. This helps construct a comprehensive picture of the software’s operating context, dependencies, and potential points of interaction with other systems. The data amassed here not only informs later technical stages but also can identify high-risk or high-value targets within the application.
3. Disassembly/Decompilation
Disassembly and decompilation are core technical procedures in reverse engineering for transforming machine code or bytecode back into a more readable form. Disassembly linearizes binary instructions into their assembly language equivalents, while decompilation attempts to reconstruct higher-level code representations such as C or Java. These forms reveal program logic, function boundaries, and control flow, which are essential for deep analysis and documentation.
This step enables engineers to understand not just what the software does at a high level but precisely how it performs key operations. It also uncovers embedded algorithms, encryption routines, or proprietary data handling, providing a foundation for further manual analysis. High-quality disassembly and decompilation are crucial for reliable analysis, but their output often requires careful human review due to potential inaccuracies or missing information.
4. Static Analysis
Static analysis involves examining the software’s code, file structure, and resources without running the application. Utilizing tools such as code analyzers, dependency checkers, and pattern-matching engines, engineers extract structural and semantic details—for instance, variable usage, invoked functions, and resource references. This analysis uncovers code quality issues, potential vulnerabilities, and architectural patterns, all while keeping the program in a “safe” non-executing state.
The value of static analysis is its ability to surface design flaws, detect malware signatures, and identify static dependencies. This process can be partially automated, improving coverage and efficiency, especially when analyzing large codebases or obfuscated binaries. However, certain dynamic behaviors and runtime configurations remain beyond its reach, warranting complementary dynamic analysis.
5. Dynamic Analysis
Dynamic analysis is the examination of software behavior during actual execution. By instrumenting or monitoring the program as it runs, practitioners observe how it handles inputs, manipulates memory, makes system calls, or interacts with external resources. This approach identifies hidden behaviors such as runtime code unpacking, network communication patterns, or conditional logic not apparent in static analysis.
Dynamic analysis is especially valuable for uncovering vulnerabilities, understanding encrypted communications, or detecting environment-specific behavior. Tools like debuggers, profilers, and sandbox environments aid in observing the impact of specific events or stimuli on program state. This stage often validates hypotheses formed during static analysis and helps prioritize areas for further scrutiny.
6. Modeling and Documentation
Modeling and documentation translate analysis findings into structured representations and records that can be shared and referenced. Engineers create flowcharts, class diagrams, call graphs, or data structure summaries, detailing how software components interact and evolve. Good documentation preserves tribal knowledge, explains system intricacies, and enables onboarding of new engineers or auditors.
Comprehensive documentation is vital for downstream activities such as migration, refactoring, or compliance validation. It standardizes knowledge transfer, reduces learning curves, and empowers decision-making for further development, security assessment, or integration projects. Well-maintained models form the foundation for future system evolution and ongoing maintenance.
7. Validation
Validation ensures that the insights and artifacts generated through reverse engineering accurately reflect the original software’s functionality. Engineers cross-check reconstructed logic, configurations, or API behaviors against observed system executions and available requirements. This phase may use regression testing, comparison with original outputs, and peer reviews to certify reliability.
A robust validation process is essential for building confidence in migration efforts, security patches, or interoperability components derived from reverse engineering. It mitigates the risk of introducing errors, omissions, or misinterpretations, ensuring any derived software or documentation genuinely matches the system’s intended purpose and performance.
Tips from the expert

What Is AI-Assisted Reverse Engineering (AIARE)?
AI-assisted reverse engineering (AIARE) uses artificial intelligence to automate and accelerate traditional reverse engineering tasks. By integrating pattern recognition, machine learning, and behavior analysis, AIARE enhances code analysis, vulnerability detection, and software optimization, making it a valuable tool in both cybersecurity and software maintenance.
One of the main benefits of AIARE is automation. AI tools can decompile binaries, identify structural patterns, and suggest patches for known vulnerabilities based on historical data. This dramatically reduces the time and effort required for manual inspection and debugging. In malware analysis, AI models can classify new threats by behavior observed in sandbox environments and predict potential exploits using real-time threat intelligence.
Productivity also improves, as AI handles repetitive or complex code review tasks, freeing engineers to focus on higher-level architectural decisions or creative problem-solving. AIARE can even reveal system inefficiencies or misconfigurations, helping teams optimize software for speed and accuracy. Beyond software, the techniques developed for AI reverse engineering in one industry—such as gaming—can be repurposed in others, like autonomous vehicles or robotics.
Despite its advantages, AIARE introduces several challenges. The reliability of AI analysis depends heavily on the quality and diversity of its training data. Poor datasets can lead to false positives, missed vulnerabilities, or biased outputs. Additionally, many AI models function as black boxes, offering little transparency into how decisions are made.
Legal and Ethical Considerations of Reverse Engineering
Reverse engineering exists in a complex legal and ethical landscape. Depending on jurisdiction, reverse engineering may be permissible for purposes such as interoperability, security research, or educational use—but often prohibits circumvention of digital rights management or unauthorized redistribution. Legal frameworks like the DMCA in the United States or the EU Software Directive provide nuanced allowances and restrictions, making it critical for engineers to consult legal counsel before engaging in such activities.
Ethically, reverse engineering raises questions about intellectual property, user privacy, and responsible disclosure. Security researchers may uncover vulnerabilities through reverse engineering, but must follow disclosure protocols to prevent exploitation and respect vendor relationships. Practitioners should assess each scenario’s intent and impact, striving to advance security, knowledge, or innovation without infringing on copyrights or violating confidentiality.
Best Practices for Successful Reverse Engineering in Software Engineering
1. Maintain Comprehensive Documentation
Maintaining comprehensive documentation throughout the reverse engineering process is essential for ensuring clarity, reproducibility, and knowledge transfer. As engineers progress through analysis and refactoring, they should record findings, tool configurations, assumptions, and encountered obstacles. Clear diagrams, structured reports, and annotated source code help both present and future teams understand rationale behind key decisions, preventing knowledge loss and reducing the risk of redundancy.
Documentation also aids in compliance, auditability, and external collaboration. Regulatory environments or multi-party projects may require detailed logs of actions, discoveries, and code changes. By making documentation a continuous and disciplined practice rather than a post-hoc task, teams dramatically reduce onboarding time for new engineers and protect against miscommunication or undocumented shortcuts.
2. Validate Findings in Isolated Environments
Validating findings in isolated environments, such as virtual machines or sandboxed testbeds, is crucial for both safety and reproducibility. This technique protects the production environment from potential instability, malware, or accidental data corruption during analysis and experimentation. Controlled settings allow careful observation of system responses to changes, input manipulation, or code injections without compromising business operations or sensitive data.
Isolated validation further enables accurate regression testing, reproducible bug tracking, and safe integration with other components. By separating the experimental process from live systems, teams can iterate quickly, log all activity, and roll back unwanted changes efficiently. This practice reinforces confidence that reverse-engineered insights and software behave as intended in constrained, risk-free contexts.
3. Understand Code and Data Structures
A deep understanding of code and data structures is a fundamental requirement for effective reverse engineering. Practitioners must identify and study language-specific constructs, calling conventions, and memory layouts to reconstruct the program’s logic accurately. Proficiency in reading assembly language or low-level representations is often necessary when navigating disassembled binaries or system dumps, as is an appreciation for common compiler optimizations and system APIs.
Deciphering proprietary data structures or serialization formats is equally important. Reverse engineers may encounter custom protocols, hidden metadata, or complex object hierarchies embedded in files or network streams. Detailed analysis of these structures helps teams correctly interpret program state, data flows, and external communications, ensuring derived documentation and modifications remain reliable and consistent with the original application.
4. Coordinate with Cross-Functional Teams
Reverse engineering often intersects with various disciplines, including security, systems integration, and compliance. Coordinating with cross-functional teams—such as developers, network administrators, and business analysts—enriches the analysis with broader perspectives. Technical and domain-specific expertise can clarify ambiguous behaviors, suggest alternative approaches, and prevent blind spots in documentation or testing.
Active collaboration also simplifies the process of integrating reverse-engineered findings into ongoing projects or operational environments. Cross-team communication improves requirements alignment, synchronizes updates, and avoids conflicting changes or security issues. Proactive engagement ensures that the reverse engineering effort is aligned with organizational objectives and leverages collective knowledge for better outcomes.
5. Integrate Version Control for Reverse Engineered Artifacts
Integrating version control for reverse engineered artifacts brings rigor and visibility to the iterative process. By tracking changes to disassembled code, documentation, and analysis scripts using modern version control systems like Git, teams establish audit trails, enable collaboration, and enable rollback in case of errors. This structure supports parallel review of hypotheses and experiments, reducing loss of intermediate insights.
Version control is not limited to reconstructed source code; it also extends to models, diagrams, and binary diff records. Granular tracking of artifacts enables teams to reconstruct decision logic, verify attribution of discoveries, and seamlessly coordinate updates during long-term projects. The discipline of systematic versioning instills best practices into every phase of the reverse engineering lifecycle.
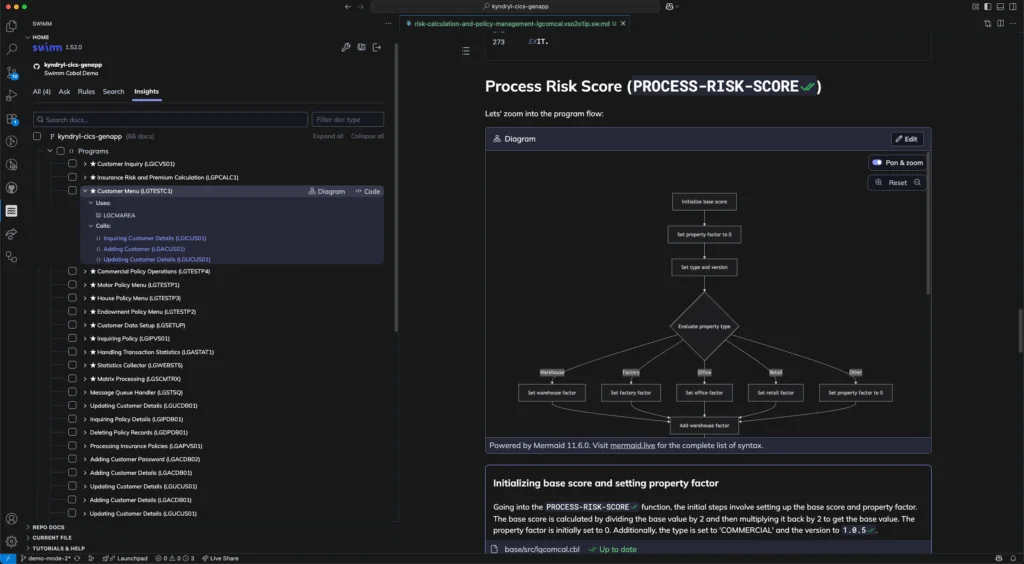
Automating Reverse Engineering in Software Modernization Projects with Swimm
Swimm’s Application Understanding Platform helps solve one of the biggest challenges in modernization – the lack of understanding of existing applications.
Swimm is able to be deployed in highly secure environments and uses deterministic static analysis and generative AI to reverse engineer applications – extracting business rules in a proven, reliable and cost-effective way.
Key features include:
- Business rule extraction: Accurately extracts all the business rules and logic in the codebase.
- Architectural overviews: Finds and explains the component architecture of the application and breaks down programs, jobs, flows and dependencies.
- Natural language: Turns vague program and variable names into descriptive names for quickly understanding connections and flows.
- Customizable support: Supports complex and proprietary implementations of COBOL, CICS, and PL/I through language parsers and company specific plug-ins.
- Trust: Deterministic static analysis enables Swimm to eliminate LLM hallucinations and deliver insights across millions of lines of code.