
If you’re working in a medium or large enterprise, chances are there’s still COBOL running somewhere in your stack—likely in the most business-critical parts. Financial systems, claims processing, mainframe batch jobs, regulatory pipelines—these aren’t just legacy systems, they’re operational core. But maintaining and evolving these COBOL systems is getting harder. The engineers who built them are retiring, documentation is spotty or missing, and the architecture is often monolithic, opaque, and hard to test. Yet rewriting everything is rarely feasible or safe.
That’s where modernization comes in: not as a one-time migration, but as a phased, risk-managed process that balances system continuity with technical progress. In this guide, we’ll walk through what COBOL modernization looks like in 2025, with a focus on practical approaches that teams are actually using in production environments. This includes reverse engineering existing systems, creating automated documentation and code maps, wrapping legacy logic in APIs, rehosting on modern infrastructure, and incrementally replacing parts of the codebase where it makes sense.
We’ll start by comparing manual vs automated modernization approaches—what can realistically be offloaded to tools, and what still needs hands-on engineering. We’ll look at common pitfalls and failure patterns, break down a step-by-step framework for modernizing COBOL systems, and share field-tested ways to safely integrate documentation, testing, and CI/CD practices into the workflow.
Swimm is part of the new AI native generation of platforms to help confidently modernize COBOL in 2025 by turning complex, aged codebases into clear information for stakeholders. When you’re dealing with knowledge gaps in your applications, complete and reliable understanding of business logic, business rule, architecture, and dependencies is essential to making decisions, reducing risk, and shortening timelines.
By the end of this guide, you’ll have a clear view of the tooling landscape, a phased approach to legacy system modernization, and a practical playbook you can adapt to your own COBOL stack. No silver bullets—just a real-world strategy for moving your infrastructure forward, safely.
Automation vs. Manual Modernization
Manually modernizing COBOL systems typically starts with assigning senior engineers to reverse-engineer code written 30+ years ago. These systems have grown organically, often with no documentation, and include deeply coupled modules, procedural data flows, and legacy infrastructure (like JCL and VSAM). Even understanding what the system does can take months.
Manual methods usually involve building spreadsheets of dependencies, drawing flowcharts, creating one-off documentation, and constantly validating assumptions through trial-and-error. This approach can work for small systems or isolated modules, but at scale, it becomes a bottleneck. More importantly, it’s hard to validate, harder to transfer, and nearly impossible to maintain once the original engineers move on.
That’s why most successful modernization efforts in 2025 now incorporate automation from day one. Specifically, teams are using tooling that can extract structure, generate documentation, surface business logic, and reduce the time spent understanding the legacy system before any migration begins.
A good example of this approach is with Swimm. As Application Understanding Platform built to support modernization by automating codebase understanding, Swimm integrates into your repo and CI/CD pipeline and is designed to make legacy systems—including COBOL—more navigable and less fragile.
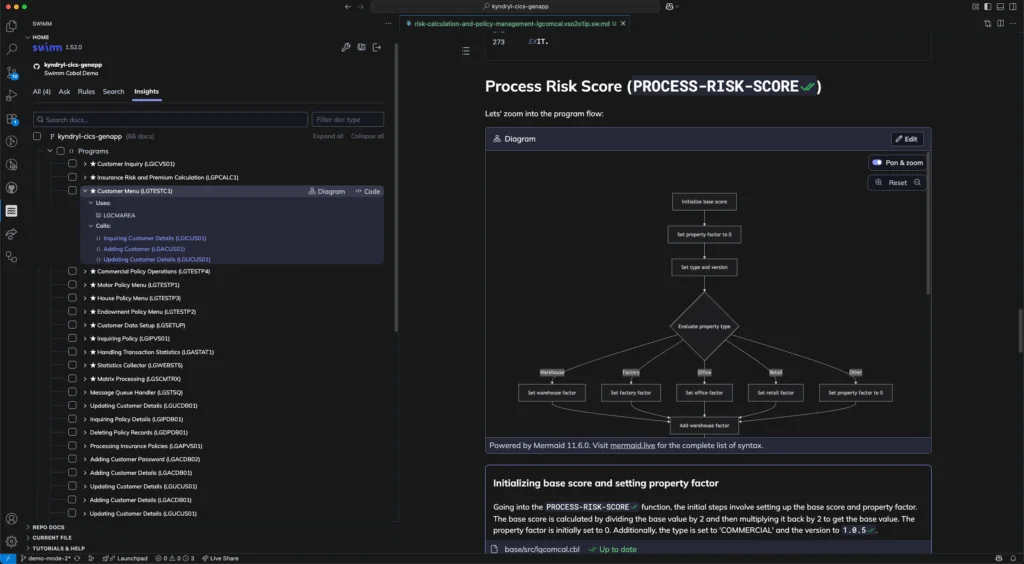
Here’s what Swimm actually does in this context:
- Automatically maps all COBOL modules and their dependencies
Useful when there are thousands of interconnected programs, copybooks, and batch jobs with unclear ownership. - Automatically extracts business logic rebuilding specs
Engineers don’t need to decode every PERFORM and EVALUATE block to get a high-level picture of what a module is doing. - Creates in-repo documentation that updates with the code
No external documents that drift from reality. Everything is stored next to the relevant logic and is part of the review process. - Improves migration success rate
With better visibility and documentation, it becomes easier to identify candidate modules for wrapping, refactoring, or replacement—reducing errors and time spent backtracking. - Shortens onboarding time for new engineers
Legacy COBOL code isn’t intuitive, but with up-to-date, linked documentation that surfaces directly in the IDE, engineers spend less time asking around and more time delivering.
Manual reverse engineering can’t offer this level of insight or consistency. And while automation doesn’t replace human judgment, it dramatically reduces the overhead of building and maintaining a working knowledge of a legacy codebase.
In practice, the combination of structured documentation, automatic mapping, and integrated workflows makes automated tools a practical necessity—not a luxury—when dealing with critical COBOL systems. Manual methods might get you there eventually, but the time and risk involved usually don’t justify the delay.
Common Modernization Challenges
Modernizing COBOL systems isn’t technically difficult because COBOL is hard to write—it’s difficult because of everything around the code: architecture, dependencies, processes, people, and risk. These are the issues that stall projects, blow up budgets, or quietly get kicked down the road for another year. If you’re trying to modernize or migrate a COBOL system in 2025, these are the things you’re almost guaranteed to run into.
Monolithic structure with hidden dependencies
COBOL systems weren’t designed with modularity in mind. Over time, changes have been layered on top of each other with little to no isolation. Business logic, I/O handling, and scheduling are often tangled together. What looks like a single batch job can trigger updates in multiple systems or files. Changing one line in one module might break another you didn’t even know was connected. Without clear maps of how programs and files relate, you end up guessing—or freezing.
No accurate documentation
Most COBOL systems in production today don’t have reliable documentation. You might find a few PDFs or old Visio diagrams, but they’re usually outdated or partial. Institutional knowledge is another story: it often lives with one or two engineers who have been around for 30 years and are now counting down to retirement. When that knowledge disappears, even a restart script can turn into a multi-day recovery effort.
Limited COBOL expertise
You’re not hiring a team of COBOL engineers in 2025—at least not easily. Most engineers coming in are fluent in modern stacks and haven’t touched a mainframe. Without current documentation and system-level understanding, these developers are stuck. Even experienced devs won’t take ownership of code they don’t trust or understand. The result: bottlenecks, blocked PRs, and stalled modernization projects.
Integration complexity
Getting COBOL modules to “talk” to modern systems isn’t just a technical problem—it’s a design one. These programs weren’t built to expose APIs or handle real-time requests. Data access might be locked inside flat files or VSAM datasets. You can wrap some logic, but not all of it. Without a clear view of what each module does and what depends on it, integration becomes trial and error. That’s fine in test. Not in production.
High-risk systems with low fault tolerance
A lot of COBOL runs the core of the business—billing, policy issuance, payment clearing. You can’t afford downtime or silent failures. But when you’re touching old systems with minimal test coverage, change risk is high. If you don’t have a clear understanding of dependencies or logic paths, you’re flying blind. And “safely modernizing” starts to sound like a contradiction.
Step-by-Step Modernization Roadmap
Once you’ve accepted that full rewrites are risky and slow, the goal becomes phased modernization—breaking the system down into manageable, understandable units and modernizing one piece at a time without breaking production. The process isn’t linear, but there’s a basic sequence that’s proven to work in real teams, especially when backed by tooling that reduces ambiguity and manual effort.
1. Understand the Codebase
You can’t modernize what you don’t understand. Start by mapping the structure of the system: entry points, key programs, job flows, file dependencies, and external interfaces. This means looking at JCLs, copybooks, and the main COBOL modules. The goal is to get a functional map of what’s where and what it touches.
Manual codebase discovery can take weeks—even months—especially when key people have left and the system evolved without documentation. This is where Swimm is useful. It builds automated dependency maps across the entire COBOL codebase, visualizing how programs are connected and what each module does, based directly on the code.
With Swimm in place, engineers get a live map of the system—automatically generated and updated—so onboarding, triaging, or planning a migration isn’t starting from scratch every time.
2. Treat Documentation as Code
Docs are only useful if they’re up to date, live alongside the code, and easy to maintain. One-pagers on a shared drive or PDFs from a training folder don’t work in a modern environment.
Use a docs-as-code approach: store documentation in the same Git repo as the COBOL code, review it in PRs, and automatically sync it when code changes. Swimm supports this pattern directly—it generates documentation linked to specific code blocks and keeps it in sync through your CI pipeline.
That way, even as the modernization effort progresses, your documentation doesn’t fall out of date, and your team has a reliable source of truth.
3. API Enablement & Wrapping
Not everything needs to be rewritten. Often, the fastest way to modernize a COBOL module is to expose its core logic behind an API. Start by identifying stable, well-understood modules. These are good candidates for wrapping with REST or gRPC endpoints.
Swimm helps here too—once you’ve mapped the program and its logic paths, it becomes easier to define the API surface: inputs, outputs, side effects. Having this clarity also reduces surprises in production, since you can spot unintended dependencies or shared state earlier.
For practical guidance, this post on overcast.blog walks through an incremental API strategy specifically for legacy systems.
4. Containerization & Rehosting
Some COBOL workloads can be moved “as-is” using rehosting. If your goal is to get off physical mainframes but not rewrite, tools like AWS Mainframe Modernization or Micro Focus Enterprise Server let you rehost COBOL apps in containerized or cloud environments.
This step requires clean packaging and stable orchestration. Many teams containerize wrapped APIs first, then gradually migrate batch jobs. Tracking all changes in documentation (via Swimm or similar) helps keep this maintainable over time.
5. Refactor, Rewrite & Migrate
Eventually, some parts of the codebase will need to be rewritten—either in Java, C#, or modern procedural languages. This step is higher risk and higher cost, so it’s best done only after you understand the legacy logic and know what it actually does.
Swimm can support this stage by keeping the legacy and new code aligned during migration, especially when refactoring is happening module-by-module. If done right, you can preserve the business logic while improving maintainability and testability.
6. CI/CD and Regression Testing
Once legacy code is wrapped or migrated, it needs to live in a modern CI/CD process. That means test coverage, pipelines, and automated validation. Tools like IBM zUnit or custom test harnesses can help for COBOL-specific workloads, but you’ll also need to define semantic equivalence tests—ensuring the new service behaves exactly like the old one.
Documentation that’s embedded and versioned with the code is critical here, especially for test case explanations, data setup scripts, and edge cases. Swimm lets teams document these artifacts in-line so they don’t live in a separate, forgotten system.
Wrapping Up
COBOL modernization doesn’t have to mean ripping everything out or rewriting millions of lines of legacy code. In most cases, the safer and more realistic approach is incremental: understand the system, document as you go, expose APIs where it makes sense, and gradually refactor or rehost based on business priorities.
If there’s one theme throughout this guide, it’s this: you can’t modernize what you can’t understand. That’s why documentation and visibility are foundational. Tools like Swimm help teams build that foundation—automatically mapping dependencies, surfacing business logic, and keeping documentation up to date as the system evolves.
A practical next step is to identify one well-scoped module, map it, document it properly, and run a small modernization cycle end to end. Doing this with the right tooling in place reduces the risk and gives you a pattern you can reuse across the rest of the system.
Thanks for reading. If you’ve been through a COBOL modernization or are in the middle of one, feel free to share your experience or questions in the comments. Would love to hear what’s worked, what hasn’t, and what you wish someone had told you earlier.