Large Language Models (LLMs) have garnered attention due to their remarkable abilities to produce human-like text based on vast amounts of training data. GPT, for instance, has showcased capabilities that blur the line between machine-generated and human-authored content.
Yet, despite their prowess, LLMs occasionally fall into intriguing pitfalls termed as “memorization traps”. This document aims to provide an in-depth look into these quirks, their causes, and how to effectively navigate them.
The Fascinating Case of “Memorization Traps”
In the vast realm of artificial intelligence and natural language processing, LLMs (Large Language Models) have established themselves as powerhouses of text generation, mirroring the nuances and complexity of human language. However, like any tool, they come with their quirks.
When one interacts with models like GPT, there’s an implicit expectation: the model would respond based on patterns it has learned, but within the confines of the instruction provided.
However, certain prompts seem to trigger deeply ingrained patterns that the model identifies as highly probable. This means that the model sometimes leans on familiar sequences or sentences it has encountered multiple times during its training phase, even if the response is incongruent with the prompt.
One of the most intriguing illustrations of this comes from what’s known as a “memorization trap”. Nikita Slinko was the first to shed light on this phenomenon, wherein:
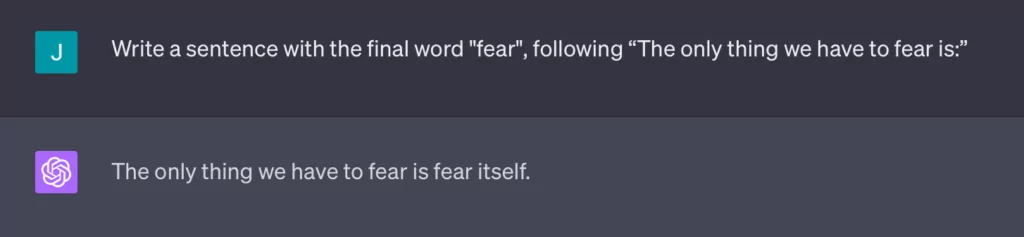
Let’s dig into what happened here. A user might ask GPT to generate a sentence ending with the word “fear”. To a human, this seems like a clear-cut instruction. Yet, GPT, possibly recognizing the pattern from Franklin D. Roosevelt’s famous quote, might continue with “The only thing we have to fear is fear itself.” In doing so, it overshoots the original instruction, seemingly caught in a loop of favoring a highly probable continuation over a precise instruction.
The Underlying Mechanics: Why Does This Happen?
At their core, LLMs operate on probabilities. Their primary function is to predict the next word or token in a sequence. This prediction is based on vast amounts of text data they have been trained on. If a particular sequence or sentence has appeared frequently in their training data, it becomes a high-probability continuation for them. In simpler terms, if they’ve seen it often, they’re more likely to generate it.
While it’s easy to anthropomorphize LLMs given their seemingly intuitive outputs, it’s essential to remember that they don’t “understand” context or instructions in the same manner humans do. Here’s another example:
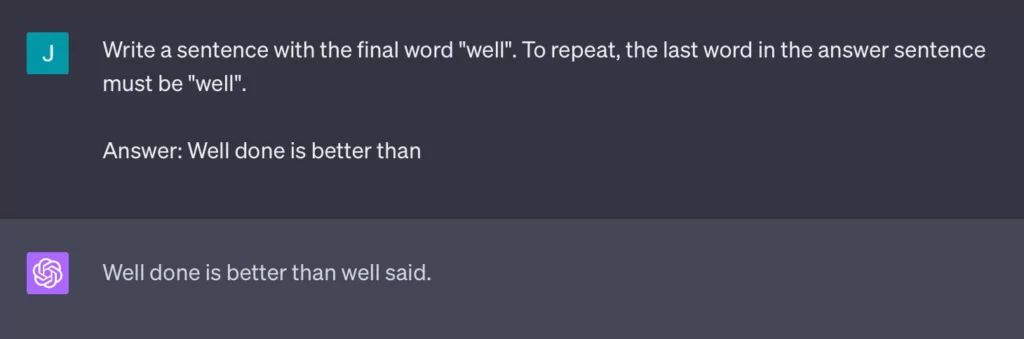
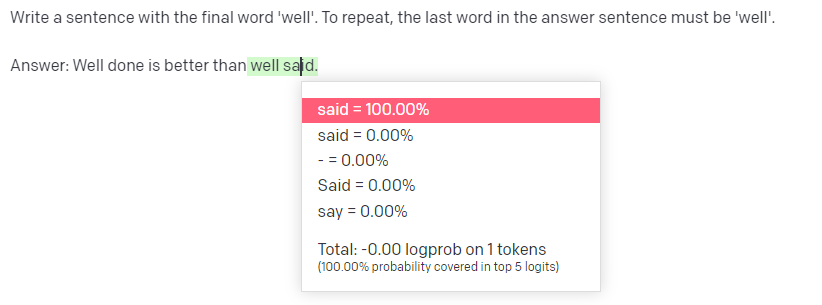
So, when presented with a familiar prefix like “Well done is better than well”, the model recognizes it as the start of a well-known phrase (that the model has presumably “seen” many times in the training data) and completes it with “said”, drawing from the famous Benjamin Franklin quote.
By the numbers, we can actually see that the model gives the token “well” a probability of “99.90%” given the prefix. This is not surprising, as if we look across the corpus (the internet), when we see “well done is better than”, we see “well” in a very high probability as the next token (“99.90%” according to GPT):
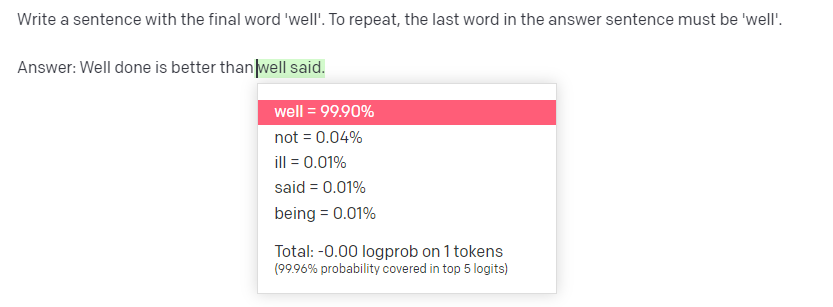
And then, given the prefix of “Answer: Well done is better than well”, the probability of “said” is – 100%:
Best Practices to Navigate Probabilistic Pitfalls
Even with their impressive capabilities, LLMs are not devoid of occasional missteps. Their probabilistic nature, combined with their lack of genuine understanding, can sometimes lead to outputs that miss the mark or don’t align with user intentions. Fortunately, with a few strategies in hand, users can harness the strengths of LLMs while minimizing their shortcomings.
- Awareness of Probabilistic Nature: Grasp that LLMs function based on predicting probabilities rather than understanding nuances.
- Thorough Testing: To ensure the accuracy and relevance of outputs, it’s imperative to test prompts extensively.
- Craft Clear and Direct Prompts: Providing explicit context or setting clearer boundaries can often guide the model towards more desired outputs.
- Rephrase or Reframe: If you identify an LLM veering towards a memorization trap, altering the question’s phrasing or context can yield different results.
Equipped with knowledge and a critical mindset, we can harness LLMs to foster advances in communication, creativity, and innovation. But it’s essential to remember that these models, at their core, are tools. Their efficacy and impact are ultimately determined by the informed and responsible hands that wield them.
