
Most enterprise financial systems weren’t built to be flexible. Payment engines, settlement layers, internal ledgers, risk assessment models—many of them are still running on mainframe infrastructure or batch-driven platforms that date back decades. These systems often carry decades of business-critical logic but have little to no documentation, are difficult to test, and are tightly coupled to everything else. And yet, they’re expected to stay online, integrate with real-time APIs, comply with new regulations, and support increasingly fast product cycles.
This is why modernization isn’t optional anymore. It’s necessary just to keep moving at the pace the business expects. But “modernization” doesn’t mean rewriting everything. In 2025, successful teams take a phased, incremental approach that reduces risk, improves visibility, and keeps existing systems running while evolving toward something more maintainable.
This guide is built for engineering leads and architects who are deep in the problem: navigating legacy code, planning phased migrations, working with compliance constraints, and balancing technical debt against delivery pressure. The goal is to offer a clear, practical path forward.
Here’s what you’ll get:
- Why modernization is urgent and unavoidable in financial systems today
- Manual vs. automated approaches, and how to tell what fits
- A proven, step-by-step framework for modernization
- How to integrate documentation and CI/CD from day one
- What tooling supports visibility, safety, and faster migration
One practical tool worth knowing at this stage is Swimm, an Application Understanding Platform, built to support modernization by automating codebase understanding—mapping modules, surfacing business logic, and keeping docs current via CI. For financial systems with decades of undocumented complexity, that kind of clarity makes a huge difference.
Now let’s dive into the two primary approaches—manual vs. automated—and what makes each one succeed or fail in the real world.
Automation vs Manual Modernization of Financial Apps
The difference between manual and automated modernization isn’t just speed—it’s sustainability. Manual efforts can technically work, but they’re rarely repeatable, and almost never scalable. Most teams start out manually: assigning engineers to analyze legacy modules, chase down undocumented dependencies, and create static docs in Confluence or shared drives. But this quickly breaks down in financial systems where a single application can span hundreds of interdependent jobs, and even small changes have regulatory and operational impact.
Manual discovery also relies too heavily on institutional knowledge. Once those people leave—or worse, forget—you’re stuck. Documentation gets stale. Every onboarding cycle resets the knowledge curve. Worst case, something breaks in production, and nobody understands why.
Automated approaches aim to replace this fragile process with something trackable and maintainable. You don’t need to document every line of COBOL or every JCL entry point by hand. Tools now exist that can parse the structure, extract relationships, surface business logic, and help the team maintain understanding as the system changes.
One tool that’s proving useful in this area is Swimm. Unlike static knowledge platforms, Swimm integrates with your actual codebase and CI. That means documentation lives alongside the code, updates with every PR, and reflects how the system actually behaves—not how someone thought it behaved six months ago.
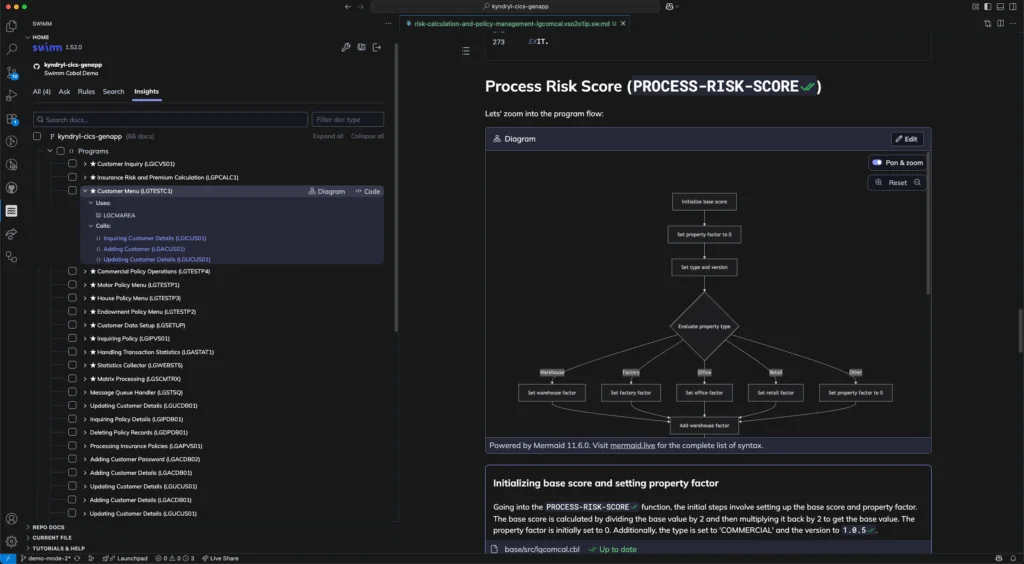
In a financial modernization context, here’s how Swimm can reduce friction:
Automatically maps all COBOL and legacy modules and their dependencies
This helps surface coupling and identify safe points for API wrapping, refactor, or retirement.
Auto-generates system specs and extracts business logic
Engineers can understand what modules do without tracing every execution path manually.
Keeps documentation up to date
Docs are part of the code review process, preventing drift.
Improves migration success rate
More clarity means fewer surprises during transitions—especially when wrapping legacy logic or rehosting modules.
Reduces onboarding time
New engineers get context directly in the IDE, without waiting on one-on-one walkthroughs or tribal handoffs.
The key is that automated documentation and mapping isn’t just “nice to have.” In modernization projects with decades of complexity, it’s the only way to reduce knowledge risk and increase throughput over time. That’s why automation here isn’t about productivity—it’s about safety and repeatability.
In the next section, we’ll go deeper into what actually makes financial systems so hard to modernize, and how to structure your approach to avoid the usual traps.
Major Challenges in Financial Applications
Most legacy financial platforms are large, opaque, and interconnected in ways that aren’t always obvious. Systems built over decades typically lack clear separation of concerns—batch jobs trigger other jobs, shared global variables pass silently between modules, and logic is often buried in decades-old COBOL or PL/I.
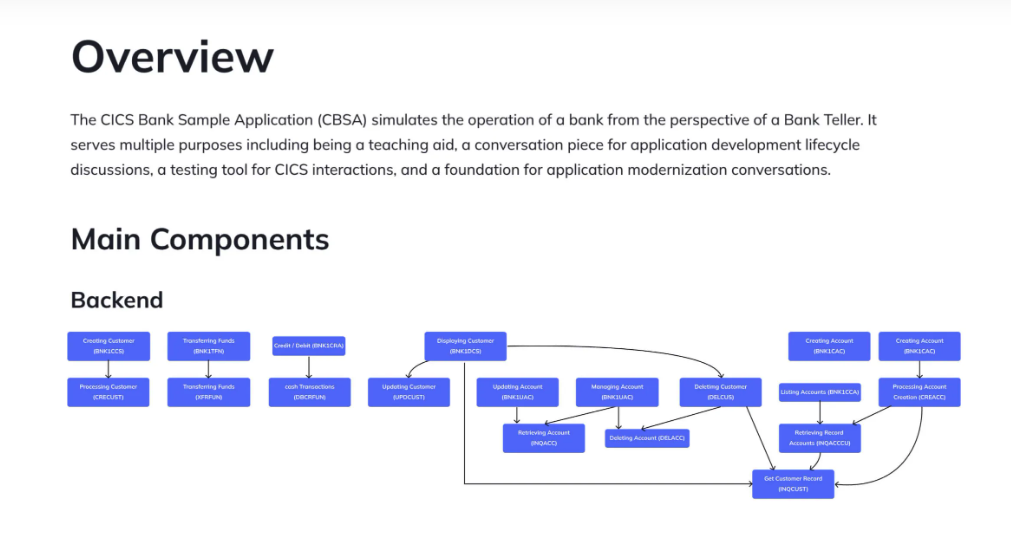
You can’t refactor what you don’t understand. But reverse-engineering this kind of environment manually is slow, error-prone, and often incomplete. This is where tools like Swimm become useful: by scanning your existing codebase, Swimm automatically surfaces module boundaries, maps internal dependencies, and builds documentation around those insights. That gives you a visual and semantic map of what’s actually running—before you touch a line of code.
Extracting Business Logic Hidden in Code
In many systems, the actual “business logic” is tangled with control flow, error handling, and data transformations. Even understanding what a module does—say, calculating risk exposure or settlement fees—requires digging through procedural code with little or no documentation.

Swimm helps here by generating system specs and summaries based on the code itself. It doesn’t try to describe everything. Instead, it focuses on surfacing logic patterns, API contracts, and execution flows in a way that engineers can reason about. When you’re dealing with risk-sensitive logic, it’s a lot easier to wrap or refactor something if you can confirm its intent and structure up front.
Mapping Module Dependencies Across Systems
Another common blocker is the lack of visibility into how modules interact. One COBOL program might trigger a chain of downstream updates. A single data structure might be used inconsistently across five teams. You’re flying blind unless you can build and maintain a reliable dependency graph.
Swimm automatically detects these internal relationships and builds out a graph of module dependencies. That makes it possible to understand which components are safe to isolate, which are tightly coupled, and what can be extracted, wrapped, or migrated incrementally.
This kind of mapping is especially useful when you’re preparing for containerization or service wrapping. Knowing what talks to what—and how—is the first step toward decoupling.
Dealing with Sparse or Obsolete Documentation
Even when docs exist, they’re often stale. They might describe a flow that changed three years ago or reference systems that were deprecated last quarter. Without a mechanism to keep documentation in sync with reality, you’re just creating more debt.
Swimm handles this by embedding documentation directly in the codebase, versioned alongside the source. It’s updated through the same PRs and CI pipelines as your code, which prevents drift over time. You’re not writing static wiki pages—you’re maintaining living documentation that evolves with the system.
Step-by-Step Modernization Roadmap
With a clear understanding of your system’s complexity and documentation challenges, you can move confidently into a phased approach. Each phase builds deliberately on the last, combining manual oversight with automation to reduce risk and increase velocity.
1. Understand and Map the Legacy System
Start by feeding your COBOL source, JCL, and configuration scripts into tools that can parse code structure and control flow. Automated mapping surfaces module boundaries and interdependencies—without manual spelunking. With clear visuals of what talks to what, you’ll have confidence about where it’s safe to make changes, wrap services, or extract logic.
Using a platform like Swimm here gives you live dependency maps. It automatically tracks program graphs and highlights coupling, helping to identify APIs to expose or modules to incrementally refactor.
2. Document as Code
Once you’ve mapped modules, start embedding documentation directly into your code repository. Write high-level rationales, interface definitions, and critical assumptions next to the relevant code. Review documentation alongside code changes—it should evolve together.
Swimm supports this “docs-as-code” workflow natively: it inserts code-linked narrative blocks and keeps docs up to date via CI-driven updates, so documentation never drifts from reality.
3. Expose Core Logic via APIs
Identify stable, business-critical modules—like risk calculators, reconciliation engines, or account balance services. Define clean I/O boundaries and wrap them as REST or gRPC endpoints. Evaluate impact with integration tests before deployment.
Because your modules are now mapped and documented, you know exactly what to expose and how to validate output. This contextual clarity minimizes surprises in development and testing.
4. Incremental Rehosting or Containerization
With logic wrapped and covered by tests, you can begin rehosting. Containerizing parts of the system gives you flexibility—batch jobs run on schedulers like Kubernetes or cloud-native orchestrators with monitoring.
Swimm’s continuous documentation aids understanding as components shift environments. Having live docs on hand during packaging and deployment aids follow-through and troubleshooting.
5. Refactor and Migrate in Phases
Once key modules are extracted and tested under containerized workflows, gradual refactoring follows. You might choose to:
- Refactor code within COBOL to improve structure.
- Translate functional modules to Java, Go, or C#.
- Orchestrate business logic in microservices for better observability.
By verifying behaviors continuously—through regression tests and live documentation—you ensure functional equivalence and compliance during changes.
6. Embed CI/CD and Regression Safety Nets
Automation plays a final role here. Every commit, test, and deploy needs a reliable place in your CI/CD flow. Common practices include:
- Semantic regression tests (e.g., IBM zUnit) for legacy logic.
- Contract and integration tests for APIs.
- Chaos or resilience tests for service reliability.
Because documentation is treated like code, it’s versioned, reviewed, and updated with the same rigor—keeping onboarding, audits, and compliance processes intact.
Why This Roadmap Works
This workflow balances pragmatism with process:
- You don’t rip and replace—you evolve in place.
- You use automation where understanding fails.
- You treat documentation as a first-class development artifact.
- You deploy incrementally, backed by visible, testable contracts.
This is how engineering leaders maintain production stability, meet compliance standards, and still deliver modernization outcomes.
In the next section, we’ll dive into choosing tools and patterns that support each phase effectively—practical guidance, not theory.
Conclusion
Modernizing financial systems isn’t about hero rewrites or one big-bang migration. It’s about clarity, control, and small, deliberate steps. Start by understanding what you already have. Map it. Document it. Isolate what works and expose it. Then migrate and refactor at a pace that keeps risk low and systems online.
The hardest part is often just seeing what’s really there—especially with legacy COBOL, JCL, and undocumented logic spread across decades. That’s where tools like Swimm come in. When documentation is auto-generated from your actual code and kept current in CI, it’s a lot easier to modernize with confidence, not guesswork.
If you’re planning your own modernization path, start small. Choose one module, wrap it, move it, verify it. Then build from there. And if you’ve gone through a similar journey—or are deep in one now—I’d love to hear what’s worked for you. What’s helping? What’s blocking progress?
Drop your thoughts or questions in the comments. Thanks for reading.