When enterprise teams deploy AI coding assistants across hundreds of developers, the math changes quickly. A query that costs $0.15 and takes 45 seconds seems trivial in isolation. Multiply that by thousands of daily interactions across your engineering organization, and you’re looking at significant infrastructure costs and cumulative time losses that compound into real productivity drains.
We built SwimmBench to answer a question our customers kept asking: “Coding assistants work better with Swimm – but how much better?” This article shares what we learned from testing on a nearly 5 million line codebase, the methodology we used, and why the results matter for development leaders evaluating AI tooling investments.
Our testing shows average Claude Code response time savings of 75% and average cost savings from efficient token utilization of 61%.

The problem: AI coding assistants are expensive and slow on large codebases
Every AI coding assistant faces the same fundamental challenge when working with enterprise codebases: context. Large Language Models can only process limited context windows, and finding relevant code in millions of lines requires exploration – whether through grep, file reads, or agent-based search.
This exploration has real costs:
- Token costs accumulate: Every file read, search result, and exploration step consumes tokens. On a 2-million-line codebase, answering architectural questions can require reading hundreds of files.
- Latency compounds: Each exploration step adds seconds. Complex questions that require tracing flows across multiple files can take minutes to answer.
- Quality varies: Without complete context, AI assistants often miss critical dependencies or provide incomplete explanations.
The question isn’t whether AI coding assistants are useful – they clearly are. The question is whether providing them with pre-indexed, comprehensive code understanding can meaningfully improve their cost, speed, and output quality.
What we built: SwimmBench – a benchmarking tool for AI code tasks
SwimmBench is an internal benchmarking framework designed to measure how different context approaches affect AI agent performance on code understanding tasks. We built it because no standard methodology existed to compare “AI assistant with a context layer” versus “AI assistant with native exploration capabilities.”
The benchmark stack
SwimmBench combines three components:
- Promptfoo: An open source evaluation runner that handles test orchestration, metric collection, and result aggregation
- Claude Code: Anthropic’s AI coding agent with built-in codebase exploration capabilities (grep, glob, read, task agents)
- Real codebases: Production-scale repositories that represent actual enterprise complexity
What we measure
The benchmark captures metrics across five dimensions:
Cost metrics
- Total USD cost per query
- Token breakdown: input tokens, completion tokens, cache reads, cache creation
- Per-model pricing (Haiku, Sonnet)
Latency metrics
- Total response time in seconds
- End-to-end timing data
- Time spent in exploration versus generation
Quality metrics (0-5 scale)
- Completeness: Does the answer cover all relevant aspects?
- Correctness: Is the information accurate?
- Specificity: Does it reference actual code elements?
- Overall score: Weighted aggregate across dimensions
Tool usage metrics
- Number of conversation turns required
- Tool invocations by category (Read, Write, Bash, Task)
- Exploration depth before answering
An important distinction
Claude Code has sophisticated built-in codebase exploration. It can grep for patterns, glob for files, read source code, and spawn task agents for complex searches. We are not comparing “with indexing” versus “without indexing.”
We are comparing two approaches:
- Swimm Deep Index: Pre-computed, comprehensive code understanding that provides immediate access to relevant context
- Claude Code native exploration: The AI agent’s built-in ability to explore codebases using its standard toolset
Both approaches can find relevant code. The question is how they compare on cost, speed, and output quality when answering the same questions.
The test: ScummVM – 4.87 million lines of production C++
Selecting the right test codebase matters. We needed something that represented real enterprise complexity without proprietary constraints.
ScummVM fit our requirements:
- Scale: ~5 million lines of C++ code across 177k+ commits
- Complexity: 154 game engine implementations with intricate cross-file dependencies
- Maturity: 24 years of active development (since 2001) with 856+ contributors
- Open source: Allows reproducible benchmarking and external validation
Test categories
We designed evaluation prompts across two primary task types:
Architectural and flow questions
- “How does the audio subsystem initialize?”
- “What is the rendering pipeline for ScummVM’s graphics engine?”
- “Explain the save/load game mechanism and all files involved”
These questions require understanding code flows that span multiple files and directories – exactly the type of queries that stress both exploration capability and context comprehension.
Explanation tasks
- “Explain what this function does and why it exists”
- “Document the purpose and behavior of this class”
- “What are the key abstractions in this module?”
These tasks test whether the AI can provide accurate, complete explanations when given appropriate context.
Results: What we found
Here’s what the data shows:
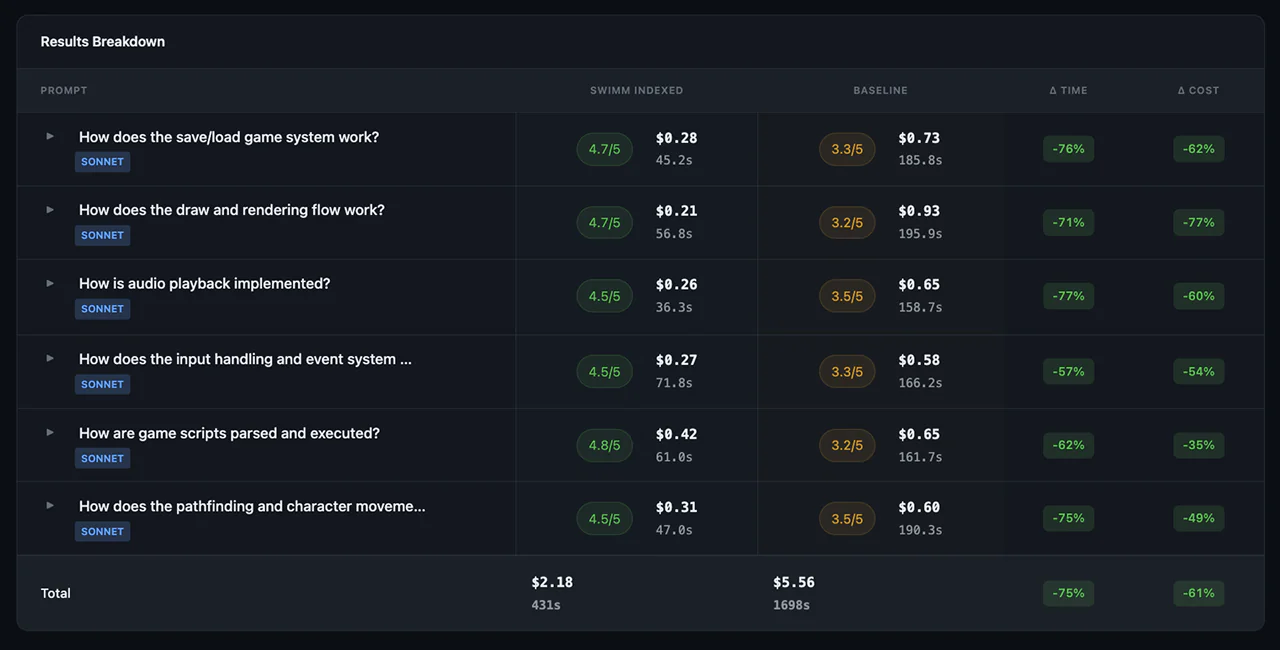
Cost reduction
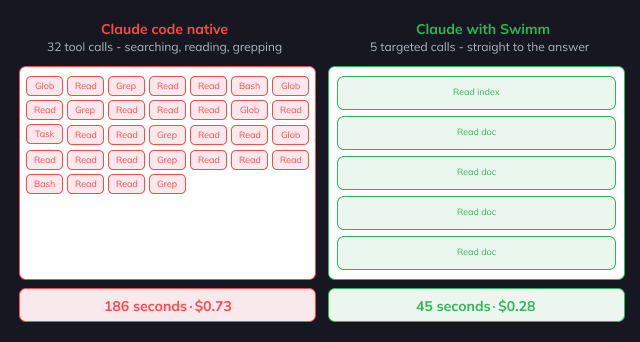
Across architectural and flow questions, the Swimm Deep Index approach showed meaningful cost reduction compared to Claude Code native exploration. The savings came primarily from:
- Reduced exploration overhead: Instead of reading dozens of files to build context, the AI received pre-indexed understanding that captured relevant code paths
- Fewer tool invocations: Native exploration required multiple grep, glob, and read operations per query. Indexed context reduced these significantly
- Better cache utilization: Pre-indexed context enabled more efficient caching, reducing token costs on repeated queries
Faster response times
Latency improvements tracked the cost reduction pattern. Less exploration means faster answers. For complex architectural questions, the time savings were substantial – queries that required extensive file traversal with native exploration completed faster with indexed context.
Model-specific patterns
We tested Claude’s model family (Haiku and Sonnet) and observed consistent patterns:
- Cost and latency benefits appeared across all model tiers
- Quality improvements were even more pronounced with smaller models, suggesting our context layer helps compensate for reduced model capability
Methodology notes and limitations
What this is
- Internal testing: We built SwimmBench, and we tested our own product. There’s inherent bias in that structure.
- Specific task types: We tested architectural and flow questions plus explanation tasks. Results may differ for debugging, refactoring, or code generation.
- Single codebase: ScummVM is complex, but it’s one codebase.
What this is not
- Peer-reviewed research: This is product engineering, not academic publication
- Industry-standard benchmark: SwimmBench is new and hasn’t been validated by external parties
Why this matters for development leaders
If you’re evaluating AI tooling for your engineering organization, the SwimmBench results suggest several considerations:
Cost at scale
Individual query costs matter less than aggregate costs across your organization. A 61% cost reduction per query translates to meaningful infrastructure savings when multiplied across hundreds of developers making thousands of queries daily.
Consider the math:
- 200 developers
- 20 AI queries per developer per day
- 250 working days per year
- = 1 million queries annually
At that scale, cost efficiency improvements have real budget impact.
Developer experience
Latency affects flow state. A 45-second wait interrupts concentration differently than a 15-second response. When developers use AI assistants frequently throughout their day, cumulative latency affects productivity and satisfaction with the tooling.
Context quality
The quality findings highlight an important principle: AI assistants are only as good as the context they receive. Swimm’s understanding layer provides consistently high-quality context. Native AI assistant understanding is unpredictable in explanation quality while being more expensive and slower.
For application understanding on complex legacy codebases, the Swimm understanding layer approach provides a better, predictable ROI.
How Swimm fits in
SwimmBench tested Swimm’s understanding layer – our approach to providing comprehensive code context to AI tools. Here’s how it works:
Understanding as context layer
Swimm analyzes codebases using deterministic static analysis combined with AI. The result is a “deep understanding” that captures:
- Business rules and validation logic
- Execution flows and call hierarchies
- Dependencies and data flows
- Terminology mappings between code and business concepts
When an AI assistant queries the understanding layer, it receives immediately relevant context without exploration overhead. Furthermore, the AI assistant doesn’t need to parse the irrelevant context that costs money, takes time, and reduces accuracy.
The understanding layer is built once and updated as code changes meaning that the AI assistant LLM doesn’t need to transverse the codebase for each query.
Application understanding platform
Swimm’s Application Understanding Platform is the engine behind powering AI assistants and humans. The platform helps teams:
- Extract business rules from legacy code automatically
- Generate visual representations of application flows
- Preserve institutional knowledge independent of individual availability
- Accelerate onboarding for developers joining unfamiliar legacy codebases
