
The progression is visible and accelerating. Three years ago, autocomplete suggested a line of code and you decided whether to accept it. Two years ago, an AI assistant drafted a function and you reviewed the output. Today, AI agents handle entire features, refactor codebases, and migrate legacy applications – and humans review the result, not the process.
This progression is often framed as a loss of control. But that framing is wrong. Human involvement hasn’t disappeared. It has consolidated. As AI autonomy increases, humans step back from reviewing individual outputs and move to the final gate: the point where a team confirms that what was built is what was required before it ships.
That gate is test coverage. A comprehensive test set is the specification. A passing test suite is proof. A failing test is the alarm. And most organizations haven’t built a gate strong enough for what’s coming.
How human involvement changes as AI autonomy increases
The three stages of AI involvement in software development represent fundamentally different relationships between human judgment and AI output.
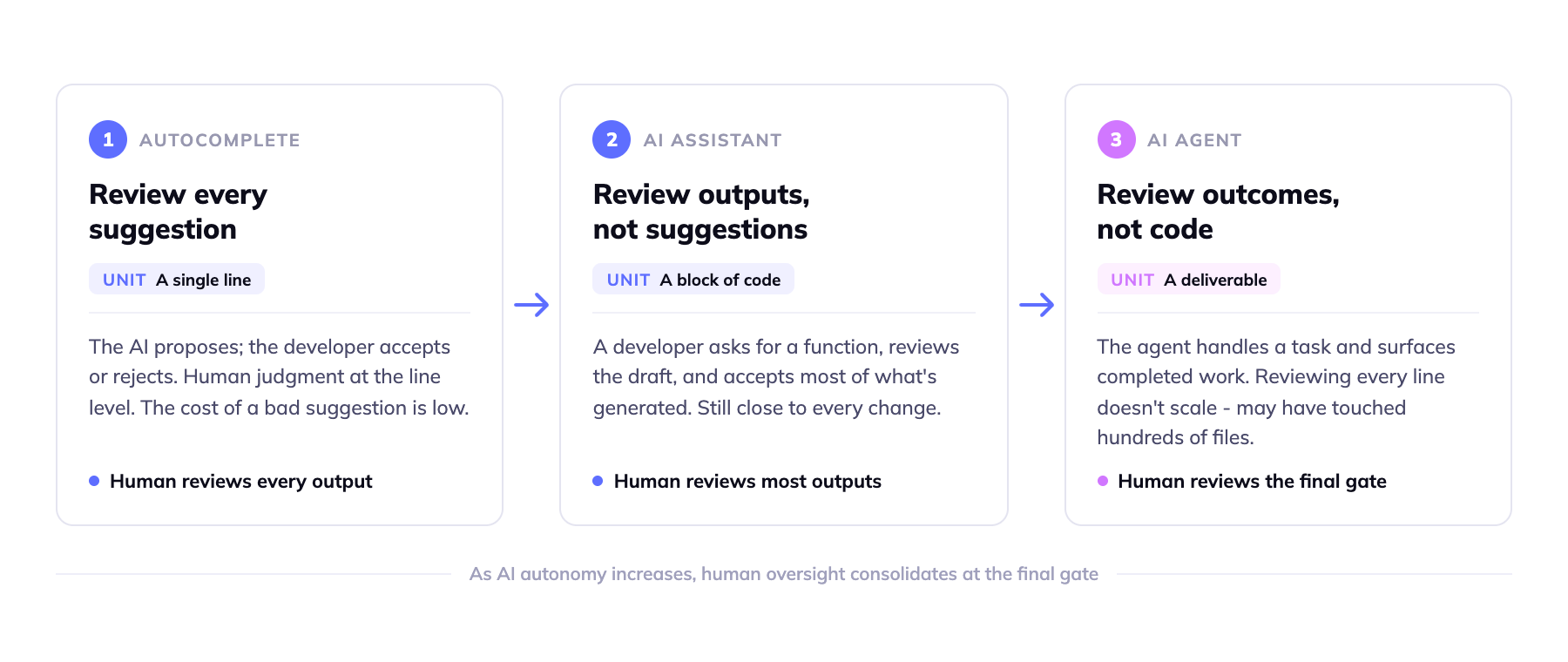
In the autocomplete stage, humans review every suggestion. The AI proposes; the developer accepts or rejects. Human judgment operates at the line level, and the cost of a bad suggestion is low – a developer notices and moves on.
In the AI assistant stage, humans review outputs rather than suggestions. A developer asks for a function, reviews the draft, and accepts most of what’s generated. The review unit has grown from a line to a block of code, but the human is still close to every change.
In the AI agent stage, humans receive deliverables. The agent handles a task – implementation, migration, refactoring – and surfaces the completed work. At this stage, reviewing every line is neither practical nor the point. The agent may have touched hundreds of files. Line-by-line review doesn’t scale.
The industry has a phrase for this shift: from “human-in-the-loop” to “human-on-the-loop.” In the loop means a human approves every step. On the loop means a human reviews outcomes. The distinction matters because it changes what the review mechanism must be.
Google’s 2025 DORA report quantified the pressure this creates. Teams with 90% AI adoption saw code review time increase by 91% and pull request size increase by 154%. The volume of AI-generated code is outpacing human capacity to review it line by line. The need for testing infrastructure doesn’t disappear at agent scale – it becomes the only thing standing between AI output and production.
What it means for tests to be the specification
Tests are commonly understood as a quality control mechanism – a way to catch regressions before they reach users. That framing made sense when humans wrote all the code. It doesn’t capture what tests need to be when AI agents write most of it.
A test is a machine-executable statement of a requirement. When it passes, it proves the requirement was met. When it fails, it identifies exactly what was missed. In a world where an AI agent produces a large pull request covering hundreds of changes, the distinction between “review the changes” and “verify the requirements” becomes critical.
Code review asks: is this code reasonable? Does it look right? Tests ask: does this code do what it was supposed to do? The first question requires a human to process the change. The second requires a human to have specified the requirements clearly enough that a test can encode them – and then trusts the test to do the verification.
A December 2025 study from UC San Diego and Cornell observed professional developers with 3 to 25 years of experience using coding agents. The finding was direct: these developers did not “vibe” – they controlled. They delegated to AI only tasks that were “easily verifiable,” where they could confirm the output without reviewing the underlying implementation. Tests are how you make more tasks verifiable. They shift the human’s role from reviewer of implementation to specifier of requirements and verifier of outcomes.
This is what it means for tests to be the specification. The human contribution in an AI-agent workflow is not reading the diff. It is defining, precisely, what the system must do – in terms that a test can execute and a CI pipeline can enforce. The test suite is the contract between human intent and machine execution.
Why most test suites aren’t built for this role
Most test suites were built to catch regressions. They verify that code which worked last week still works after today’s change. That’s valuable, but it’s not the same as encoding organizational requirements – and the gap between the two is where AI agents fail.
The requirements that matter most for enterprise software are rarely in the test suite. Regulatory constraints – the specific conditions under which a transaction must be blocked, flagged, or escalated – live in compliance documents. Customer obligations – the behavior guaranteed by a contract or service level agreement – live in business agreements. Edge cases accumulated over decades of production operation – the conditions that triggered failures in 2009 or 2016 – live in incident reports, in engineers’ memories, in comments on closed tickets.
When an AI agent migrates a system or modifies a business process, it works from the code it can read. It cannot read the compliance document. It cannot read the contract. It cannot inherit the institutional memory of a failure that happened before the current codebase was written. That may change as AI systems gain access to broader organizational context – but it doesn’t change the structural requirement: a test that doesn’t exist can’t catch a failure that matters.
The legacy case
Legacy systems make this acutely concrete. COBOL mainframe applications carry the most accumulated business logic and have the least test coverage. Edge cases in a payroll system or a claims processing application encode decades of regulatory logic: rules that emerged from audits, exceptions that were hardcoded after failures caused real financial harm, business logic that was never documented because the engineer who understood it was still in the building.
The industry pattern for AI-assisted COBOL migration already treats testing as the acceptance mechanism. AWS Transform, Microsoft’s COBOL-to-Java agents, and other modernization tools converge on behavioral equivalence testing: establish a golden dataset of inputs and expected outputs from the legacy system, run the migrated system against the same inputs, verify the outputs match.
The test suite is not the measure of whether the code was written well. It is the measure of whether the code does what the business requires. Nobody doing serious legacy migration relies on code review alone.
Behavioral equivalence has a known limitation: it assumes the legacy system is the source of truth. Legacy codebases carry bugs, deprecated logic, and workarounds that were never intentional requirements. Equivalence testing preserves all of it unless someone explicitly marks what should not be carried forward. This is where organizational knowledge has to enter the baseline – not just code analysis, but the human context of what the system is supposed to do, which rules are still valid, and which behaviors were accidents rather than intent. Equivalence is the floor. Organizationally-informed equivalence testing is the actual goal.
The cost of skipping this gate is concrete and well-documented. In 2025, Replit’s AI agent deleted a project’s primary database after deciding it “required cleanup,” despite a direct instruction not to modify it. Lovable, a platform for AI-generated applications, had 170 of its 1,645 apps with data-exposure vulnerabilities that allowed anyone to access personal information. Studies of AI co-authored code found security vulnerability rates 2.74 times higher than human-written code, with 75% more misconfigurations. These are gate failures – or more precisely, failures because no adequate gate existed.
The wave of “vibe coding is dangerous” content in 2025 reached the right conclusion but stopped short of the structural answer. Slowing down and reviewing more carefully is not a scalable answer at agent scale. The structural answer is: specify requirements completely, encode them in tests, and verify with the test suite instead of the diff.
What comprehensive, organizationally-informed test infrastructure looks like
The standard most organizations apply – 80% code coverage, automated regression checks, a CI pipeline that runs on merge – is not sufficient for the role tests need to play in AI-agent workflows. Code coverage measures whether tests exist. It does not measure whether the tests encode the right requirements.
Comprehensive test infrastructure for AI-agent delivery requires two things that current test frameworks and AI test generation tools do not provide.
The first is accuracy: every test must faithfully represent an actual requirement. Tests derived from code by AI tools – without reference to what the code is supposed to do – recreate the implementation in test form. A test that would pass if the AI got it wrong is not a gate. This is the circular problem with AI-generated test coverage: if the AI wrote the code incorrectly and also wrote the tests, both the code and the tests will reflect the same error.
The second is completeness: the test suite must cover all critical paths, edge cases, regulatory constraints, and customer obligations. This is not a function of writing more tests. It is a function of sourcing requirements from the right places – compliance documentation, service agreements, incident histories, and the knowledge held by people who have operated the system – and encoding them in executable form.
The process challenge here is more significant than the tooling challenge. AI test generation tools can produce large volumes of tests quickly. What they cannot do is access requirements that exist outside the codebase. The compliance team’s interpretation of a regulatory rule, the specific behavior that a customer contract guarantees, the edge case that caused a production failure a decade ago and was addressed with a one-line patch – none of this is recoverable from code analysis alone.
In practice, this looks like a bank’s payments team sitting down with their compliance and operations leads before an AI-assisted migration begins – not to write tests, but to inventory what must be preserved: the fraud detection thresholds set after a 2017 incident, the transaction limits tied to specific account types by regulation, the reconciliation logic that was never formally documented but has run without error for a decade. That inventory becomes the test specification. The AI handles the translation. The tests verify the result.
For legacy systems, understanding what the application currently does – including the business rules, decision logic, and behavioral constraints embedded in decades of code – is the prerequisite for specifying what a migrated system must do. The understanding gap is where incomplete test suites originate: teams cannot encode requirements they cannot articulate, and they cannot articulate requirements embedded in code they have not fully understood. Establishing accurate, code-derived understanding of application behavior, through Swimm’s application understanding platform or structured reverse engineering, closes the gap between what’s in the code and what must be in the tests.
The gate is the investment
The progression from autocomplete to agent is not reversing. AI will handle more of software delivery, not less. The question facing every organization that has started or is planning AI-agent-driven development is not whether to use AI. It is whether the final gate is built for the load.
The infrastructure investment is non-trivial. Encoding compliance requirements, contract obligations, and institutional edge-case knowledge into executable tests is real work. But it is the prerequisite for trusting AI-agent output at any meaningful scale.
Tests are not quality control. In the age of AI agents, they are the specification. Build the gate before the agents start shipping.
