
Introduction
In this post, we will discuss how to extract business logic from COBOL applications.
What are business rules?
Business rules are the rules that govern the operation of a business.
There have been many attempts to define “business rules” formally (for example, by the Business Rules Group), which stated that a business rule is “a statement that defines or constrains some aspect of the business”.
In essence, business rules are the specific constraints, conditions, and actions embedded within a software system that reflect the policies and procedures of an organization. Legacy systems contain strategic business rules that govern the business processes, whether these rules are explicit or implicit.
For example, within the process of transferring money between bank accounts, business rules would include constraints like:
- A customer cannot transfer more money than is available in their account (overdraft limits notwithstanding)
- Certain high-value transfers may require additional verification steps
- Transfers between accounts in different currencies must apply the current exchange rate
A technical definition
Some sources define Business Rules as consisting of three basic elements – Event, Condition and Action. The standard rule pattern is:
ON <Event>
IF <(Condition)>
THEN <Action>
ELSE <Action>
We will sometimes adopt this definition in this post.
A working example
Throughout this post, I will use a toy example to illustrate the process of extracting business rules from COBOL applications.
We will consider a simple COBOL program that calculates a “Risk Score” based on certain criteria. The Risk Score is then used to determine the status of an application (e.g., “Auto-Approved”, “Pending Review”, “Manual Review”).
Consider this simple flowchart:
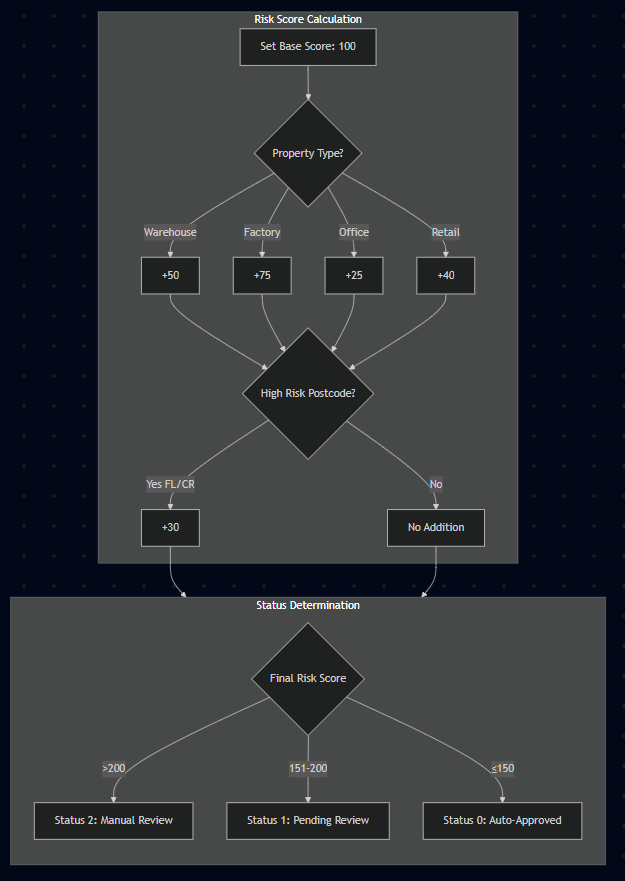
The flowchart shows the business logic for the application in a succinct and visual manner. The Risk Score is calculated based on the property type and the postcode, and then the status is determined based on the final Risk Score.
This can be broken down into many rules. An example rule from this example would be:
ON Application
IF PropertyType IS ‘Warehouse’
THEN Add 50 to Base Score
The challenge of extracting business rules from COBOL applications
Extracting business rules or business logic from applications has been a challenge for many years. In this section, we will better understand some of the challenges associated with extracting business rules from COBOL applications. This will allow us to devise a strategy to face these challenges.
As some of these challenges are technical and are closely related to the nature of COBOL and Mainframe applications, and some are non-technical, we will discuss them separately.
Technical challenges
- Scattered and intertwined logic: The business logic within COBOL systems is often scattered throughout the code. Especially in COBOL, tracking the flow of logic can be challenging, both within a single file and across multiple files. Furthermore, this logic is frequently intertwined with presentation logic, technical code, and auxiliary code. COBOL programs can have complex control flow structures, including deep calling hierarchies (PERFORMs) and sometimes GOTOs, making it hard to trace the sequence of operations that constitute a business rule.
- Technical environment complexity: A significant portion of the COBOL code (as much as 70-80% according to some sources) might be dedicated to the technical environment and infrastructure (e.g., IMS, CICS, DB2) rather than the core business logic. Identifying and filtering out this implementation-dependent logic is a major challenge. Specifically, distinguishing between data variables that are relevant to the business and those that are part of the technical framework is crucial but difficult. Technical variables (e.g., related to middleware or database interactions) need to be screened out to focus on business-related data.
- Naming Conventions: It is common for COBOL code to include cryptic variable or paragraph names that do not provide any insight into the purpose of the code.
Non-technical challenges
- Evolution over time: COBOL systems have often been maintained and evolved over many years, sometimes decades. This long history can lead to a situation where it is unclear which business rules are still actively enforced or if they are consistent with current organizational policies.
- Obsolete business logic: Legacy systems may contain obsolete business logic that was never removed from the code base. Identifying and distinguishing this from current, active rules adds to the difficulty of extraction.
- Skill shortage: It is increasingly difficult to find professionals with deep knowledge of both COBOL and the specific business domain. This knowledge gap complicates the process of accurately interpreting and extracting business rules from legacy code.
- Business knowledge loss: Over time, the original developers and business analysts who understood the rationale behind certain rules may have left the organization, taking their knowledge with them. This loss of institutional memory makes it challenging to validate extracted rules.
A roadmap and a north star
Our goal would be to extract the business rules from the COBOL application and represent them in a clear and concise manner – just like the flowchart we saw earlier.
We can define a tool that receives this COBOL code and outputs a set of business rules in a structured format, or a flowchart. For simplicity, let’s assume we want to output a set of business rules in a single flowchart.

“Level 1” – all in one file, with clear paragraph names and variable names
This example is the simplest one. Despite being unrealistic, it is a good starting point as we will have to make sure we can handle the simplest case before moving on to more complex ones.
Consider this COBOL code that implements the flowchart we saw earlier, all within a single Cobol file, with clear paragraph names and variable names:
*---------------------------------------------------------
* RISK ASSESSMENT PROGRAM
* Calculates property insurance risk scores and determines
* application status based on property attributes
*---------------------------------------------------------
IDENTIFICATION DIVISION.
PROGRAM-ID. RISK-ASSESSMENT.
AUTHOR. SWIMM-TEAM.
ENVIRONMENT DIVISION.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 RISK-SCORE PIC 9(3) VALUE 100.
01 PROPERTY-TYPE PIC X(10).
01 PROPERTY-POSTCODE PIC X(2).
01 RISK-STATUS PIC 9.
PROCEDURE DIVISION.
*---------------------------------------------------------
* Main control flow for the risk assessment process
*---------------------------------------------------------
MAIN-PROCEDURE.
PERFORM INITIALIZE-ASSESSMENT
PERFORM GET-PROPERTY-DATA
PERFORM CALCULATE-RISK-SCORE
PERFORM DETERMINE-RISK-STATUS
PERFORM DISPLAY-RESULTS
STOP RUN.
*---------------------------------------------------------
* Initialize base risk score
*---------------------------------------------------------
INITIALIZE-ASSESSMENT.
MOVE 100 TO RISK-SCORE.
*---------------------------------------------------------
* Collect property information from user
*---------------------------------------------------------
GET-PROPERTY-DATA.
DISPLAY "ENTER PROPERTY TYPE (WAREHOUSE/FACTORY/OFFICE/RETAIL): "
ACCEPT PROPERTY-TYPE
DISPLAY "ENTER PROPERTY POSTCODE (2 CHARACTERS): "
ACCEPT PROPERTY-POSTCODE.
*---------------------------------------------------------
* Calculate risk score based on property attributes
*---------------------------------------------------------
CALCULATE-RISK-SCORE.
PERFORM APPLY-PROPERTY-TYPE-RISK
PERFORM APPLY-POSTCODE-RISK.
*---------------------------------------------------------
* Apply risk adjustment based on property type
*---------------------------------------------------------
APPLY-PROPERTY-TYPE-RISK.
EVALUATE PROPERTY-TYPE
WHEN "WAREHOUSE"
ADD 50 TO RISK-SCORE
WHEN "FACTORY"
ADD 75 TO RISK-SCORE
WHEN "OFFICE"
ADD 25 TO RISK-SCORE
WHEN "RETAIL"
ADD 40 TO RISK-SCORE
WHEN OTHER
DISPLAY "INVALID PROPERTY TYPE"
END-EVALUATE.
*---------------------------------------------------------
* Apply risk adjustment for high-risk postcodes
*---------------------------------------------------------
APPLY-POSTCODE-RISK.
IF PROPERTY-POSTCODE = "FL" OR PROPERTY-POSTCODE = "CR"
ADD 30 TO RISK-SCORE
END-IF.
*---------------------------------------------------------
* Determine application status based on final risk score
*---------------------------------------------------------
DETERMINE-RISK-STATUS.
EVALUATE TRUE
WHEN RISK-SCORE > 200
MOVE 2 TO RISK-STATUS
WHEN RISK-SCORE > 150
MOVE 1 TO RISK-STATUS
WHEN OTHER
MOVE 0 TO RISK-STATUS
END-EVALUATE.
*---------------------------------------------------------
* Display assessment results
*---------------------------------------------------------
DISPLAY-RESULTS.
DISPLAY "FINAL RISK SCORE: " RISK-SCORE
DISPLAY "RISK STATUS CODE: " RISK-STATUS
EVALUATE RISK-STATUS
WHEN 0
DISPLAY "STATUS: AUTO-APPROVED"
WHEN 1
DISPLAY "STATUS: PENDING REVIEW"
WHEN 2
DISPLAY "STATUS: MANUAL REVIEW"
END-EVALUATE.
END PROGRAM RISK-ASSESSMENT.
This example is really simple, and it provides all the “help” one would need in order to extract the business rules. The paragraph names are clear, the variable names are clear, everything is implemented in a single file, there are verbose comments, the logic is very simple, and we have clear display statements.
The complexity spectrum of COBOL business rule extraction
Unlike the previous example, real-world COBOL applications rarely present their business rules so neatly. To build an effective extraction tool, we need to understand the spectrum of challenges it might face. The table below outlines the key complexity factors that make business rule extraction increasingly difficult, and how each factor can progressively escalate from straightforward to highly challenging:
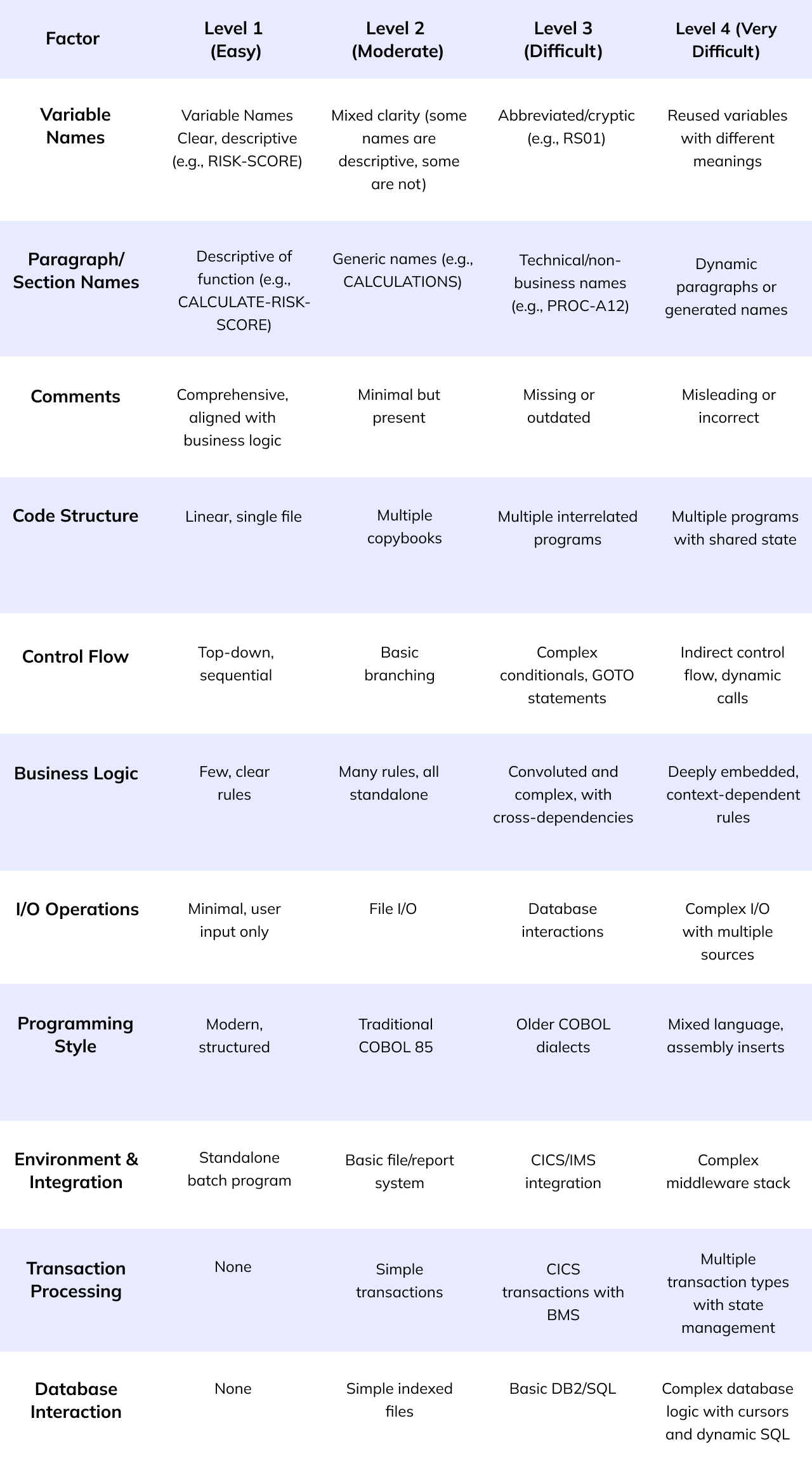
Each factor in this table represents a dimension of complexity that can be independently “dialed up” to create more challenging extraction scenarios. Starting with our simple example (Level 1 across all factors), we can gradually introduce complexity by adjusting specific factors while keeping others constant.
The overall extraction difficulty depends on combinations of these factors. For example:
- Example 1: Level 1 across all factors = Straightforward extraction
- Example 2: Level 3 Variable Names + Level 1 everything else = Moderate difficulty
- Example 3: Level 2-3 across most factors = Challenging extraction
- Example 4: Level 3-4 across all factors = Very complex extraction
For a practical challenge progression, we will increase difficulty across 1-2 factors at a time while keeping others stable, then gradually introduce more difficult combinations.
For instance, we might keep the clear paragraph names and comments but introduce cryptic variable names, forcing our extraction tool to infer meaning from context. Or we could maintain clear variables but distribute the logic across multiple files, requiring the tool to trace execution flow across program boundaries.
The beauty of this approach is that it allows for incremental development of our extraction capabilities. By tackling one complexity dimension at a time, we can build, test, and refine our tool’s ability to handle progressively more realistic COBOL applications.
It also provides a framework for measuring extraction success—each level represents a milestone in the tool’s sophistication.
Real-world COBOL systems typically fall somewhere between Levels 2 and 4 across most factors, with legacy mainframe applications often trending toward the higher end of the spectrum.
“Level 3” example – multiple files, cryptic variable names…
Below we provide the exact same COBOL program as before in terms of business logic, yet the implementation is different.
First, consider the implementation, that spans across multiple files:
Main File - RSKMNT.cbl
IDENTIFICATION DIVISION.
PROGRAM-ID. RSKMNT.
ENVIRONMENT DIVISION.
DATA DIVISION.
WORKING-STORAGE SECTION.
COPY VARDEF.
01 COMMAREA.
05 C-PT PIC X(10).
05 C-PC PIC X(2).
05 C-RS PIC 9(3).
05 C-ST PIC 9.
01 RSKMAP.
05 FILLER PIC X(12).
05 PTYIN PIC X(10).
05 FILLER PIC X(22).
05 PCDIN PIC X(2).
05 FILLER PIC X(21).
05 RSKOUT PIC 9(3).
05 FILLER PIC X(21).
05 STATOUT PIC 9.
05 FILLER PIC X(1908).
PROCEDURE DIVISION.
A100.
EXEC CICS HANDLE CONDITION ERROR(Z999)
END-EXEC.
IF EIBCALEN = 0
GO TO A200
ELSE
GO TO A300
END-IF.
A200.
EXEC CICS SEND MAP('PRPMAP')
MAPSET('PRPMSET')
ERASE
END-EXEC.
EXEC CICS RETURN TRANSID('RISK')
COMMAREA(COMMAREA)
LENGTH(16)
END-EXEC.
A300.
EXEC CICS RECEIVE MAP('PRPMAP')
MAPSET('PRPMSET')
INTO(RSKMAP)
END-EXEC.
MOVE PTYIN TO C-PT.
MOVE PCDIN TO C-PC.
EXEC CICS LINK PROGRAM('RSKPRC')
COMMAREA(COMMAREA)
LENGTH(16)
END-EXEC.
MOVE C-RS TO RSKOUT.
MOVE C-ST TO STATOUT.
EXEC CICS SEND MAP('PRPMAP')
MAPSET('PRPMSET')
FROM(RSKMAP)
ERASE
END-EXEC.
EXEC CICS RETURN TRANSID('RISK')
COMMAREA(COMMAREA)
LENGTH(16)
END-EXEC.
Z999.
EXEC CICS SEND TEXT FROM('ERR')
LENGTH(3)
ERASE
END-EXEC.
EXEC CICS RETURN
END-EXEC.
Processing Module - RSKPRC.cbl
IDENTIFICATION DIVISION.
PROGRAM-ID. RSKPRC.
DATA DIVISION.
WORKING-STORAGE SECTION.
COPY VARDEF.
LINKAGE SECTION.
01 DFHCOMMAREA.
05 C-PT PIC X(10).
05 C-PC PIC X(2).
05 C-RS PIC 9(3).
05 C-ST PIC 9.
PROCEDURE DIVISION.
P100.
MOVE C-PT TO V1.
MOVE C-PC TO V2.
MOVE 100 TO V3.
GO TO P200.
P200.
EVALUATE V1
WHEN "WAREHOUSE"
ADD 50 TO V3
WHEN "FACTORY"
ADD 75 TO V3
WHEN "OFFICE"
ADD 25 TO V3
WHEN "RETAIL"
ADD 40 TO V3
WHEN OTHER
MOVE "E" TO V5
END-EVALUATE.
IF V5 = "E"
GO TO P900
ELSE
GO TO P300
END-IF.
P300.
COPY PSTCHK.
GO TO P400.
P400.
COPY STATCALC.
MOVE V3 TO C-RS.
MOVE V4 TO C-ST.
GO TO P999.
P900.
MOVE 0 TO C-RS.
MOVE 9 TO C-ST.
P999.
EXEC CICS RETURN
END-EXEC.
Copybook1 - VARDEF.cpy
01 V1 PIC X(10).
01 V2 PIC X(2).
01 V3 PIC 9(3) VALUE 100.
01 V4 PIC 9.
01 V5 PIC X.
Copybook2 - PSTCHK.CPY
IF V2 = "FL" OR V2 = "CR"
ADD 30 TO V3
END-IF.
Copybook3 - STATCALC.CPY
EVALUATE TRUE
WHEN V3 > 200
MOVE 2 TO V4
WHEN V3 > 150
MOVE 1 TO V4
WHEN OTHER
MOVE 0 TO V4
END-EVALUATE.BMS Map Definition - PRPMSET.BMS
PRPMSET DFHMSD TYPE=MAP,MODE=INOUT,LANG=COBOL,STORAGE=AUTO,TIOAPFX=YES
PRPMAP DFHMDI SIZE=(24,80)
DFHMDF POS=(3,1),LENGTH=14,ATTRB=(NORM,PROT),INITIAL='PROPERTY TYPE:'
PTYIN DFHMDF POS=(3,16),LENGTH=10,ATTRB=(NORM,UNPROT),INITIAL=' '
DFHMDF POS=(5,1),LENGTH=16,ATTRB=(NORM,PROT),INITIAL='PROPERTY CODE:'
PCDIN DFHMDF POS=(5,18),LENGTH=2,ATTRB=(NORM,UNPROT),INITIAL=' '
DFHMDF POS=(8,1),LENGTH=12,ATTRB=(NORM,PROT),INITIAL='RISK SCORE:'
RSKOUT DFHMDF POS=(8,14),LENGTH=3,ATTRB=(NORM,PROT),INITIAL=' '
DFHMDF POS=(10,1),LENGTH=7,ATTRB=(NORM,PROT),INITIAL='STATUS:'
STATOUT DFHMDF POS=(10,9),LENGTH=1,ATTRB=(NORM,PROT),INITIAL=' '
DFHMSD TYPE=FINAL
ENDHow different is it?
Despite being a relatively simple business logic, the implementation is significantly more complex (and realistic) than the previous example. Note this this is still a very short example, and real-world applications can be much more complex.
The main differences are: (1) File Structure: The application is now split across multiple files:
- RSKMNT.CBL – Main CICS transaction program
- RSKPRC.CBL – Processing module that contains the business logic
- VARDEF.CPY – Copybook with cryptic variable definitions
- PSTCHK.CPY – Copybook with postcode risk logic
- STATCALC.CPY – Copybook with status determination logic
- PRPMSET.BMS – BMS map definition for the CICS screen interface
(2) Cryptic Elements
Variable names: are now V1 (was PROPERTY-TYPE), V2 (was PROPERTY-POSTCODE), V3 (was RISK-SCORE), V4 (was RISK-STATUS), V5 (new, represents an error flag).
Paragraph names: Changed to single letters with numbers (A100, P200, etc.)
No comments or DISPLAY statements.
(3) Control Flow
- Added GOTO statements throughout the processing module.
- Split logic across copybooks
- Added complexity with error handling and CICS transaction flow
(4) CICS Integration
- Added proper CICS commands for screen handling
- Used COMMAREA for data passing between programs
- Added BMS map definition for screen handling
The business logic remains the same
Despite all these changes, the business logic remains identical:
- Base score starts at 100 (in VARDEF.CPY and P100)
- Property type risk adjustment (in P200):
- Warehouse: +50
- Factory: +75
- Office: +25
- Retail: +40
- High risk postcode check adds 30 points for FL/CR (in PSTCHK.CPY)
- Status determination (in STATCALC.CPY):
- 200: Status 2 (Manual Review)
- 151-200: Status 1 (Pending Review)
- ≤150: Status 0 (Auto-Approved)
This complex version would present a significant challenge for business rule extraction tools while still implementing the exact same logic from your original flowchart.
Facing the challenge – example
In this section, we will consider one example of how to face the challenge of extracting business rules from COBOL applications – specifically, when the variable names are cryptic.
When trying to understand the business logic of a program by looking at its code, one of the most helpful things are names – variable names, function names, etc. I will focus on variable names, but the same applies to sections, programs etc. In Cobol, variable names are usually quite cryptic for various reasons. One of the reasons is that Cobol has a limit on the length of variable names, and developers had to come up with creative ways to name their variables. Cobol also allows only uppercase letters, digits, and hyphens in variable names, which further limits the expressiveness of variable names.
Consider this code snippet from the implementation provided earlier:
EVALUATE TRUE
WHEN V3 > 200
MOVE 2 TO V4
WHEN V3 > 150
MOVE 1 TO V4
WHEN OTHER
MOVE 0 TO V4
END-EVALUATE.Say you provide this file to an LLM to explain. The LLM simply cannot understand the meaning of V3 or V4 variables just from this file – their definitions aren’t even in this file, but rather in another one.
Let us focus on V4. From the snippet above we can see that, at least in some cases, it holds the values of 0, 1, or 2, which are not meaningful on their own. If we keep track of this variable, we can see that it is only set to these variables, and then to C-ST (within P400 of RSKPRC.cbl):
MOVE V4 TO C-STThe value within C-ST, in trun, is moved to STATOUT (within A300 of RSKMNT.cbl):
MOVE C-ST TO STATOUT.From PPPMSET.BMS, we can see that STATOUT is a single digit, and from the BMS map definition we can see that it is displayed as “STATUS:”.
DFHMDF POS=(10,1),LENGTH=7,ATTRB=(NORM,PROT),INITIAL='STATUS:'
STATOUT DFHMDF POS=(10,9),LENGTH=1,ATTRB=(NORM,PROT),INITIAL=' '
So now we know that V4 holds the status, which can be 0, 1, or 2.
To know that – we needed to track the usage of V4 (and other variables affected by it, like C-ST) throughout the codebase, and understand the context in which it is used.
Using static code analysis, we can provide the LLM with all of this relevant context from the program. But it doesn’t stop there – to understand the meaning of these variables, the LLM would need to understand the context in which they are used as part of the flow of the program.
One can suggest that by providing the entire codebase to the LLM, it would be able to understand the context in which these variables are used. Besides the downsides of cost, time and feasibility due to token limits, this approach would still not be enough. On the contrary – if there is another variable called V4 in another part of the codebase, the LLM might confuse the two, and provide inaccurate description of this specific V4 variable.
Ambiguity resolution is something that deep code analyzers excel at, and this is one way where they can complement LLMs in understanding Cobol mainframe code. A tool that performs deep-analysis of Cobol code would provide the LLM with all the context it needs in order to explain a variable, function or program – and only that context, to avoid “confusion” by the LLM.
This is only a single part of the puzzle, and there are many other challenges that need to be faced in order to extract business rules from Cobol applications, but I hope this example illustrates the point of how using LLMs in conjunction with deep code analyzers can help us understand Cobol code better.
Conclusion
Extracting business logic from COBOL applications remains a significant challenge in the modernization of legacy systems. As we’ve seen throughout this exploration, the task involves navigating a spectrum of complexities – from cryptic variable names and scattered logic to the intertwining of business rules with technical implementation details.
The roadmap we’ve outlined recognizes that this is not a one-size-fits-all problem. By categorizing the complexity factors and approaching them systematically, we can develop incremental strategies that evolve from handling the simplest cases to tackling the most convoluted legacy codebases.
What becomes clear is that modern approaches benefit from combining multiple techniques. Static code analysis tools provide the necessary context and disambiguation that LLMs need to interpret the code meaningfully. Meanwhile, LLMs offer the flexibility to understand patterns and express business logic in human-readable formats once provided with properly contextualized information.
While our simple risk assessment example illustrates the principles, real-world applications will present more diverse challenges. The approach outlined here – progressively handling increasing levels of complexity while maintaining focus on the ultimate goal of clear, concise business rule representation – provides a framework that can be adapted to various legacy modernization contexts.
By combining deep code analysis, modern AI techniques, and disciplined methodology, we can bridge the gap between decades-old implementations and contemporary business needs.
