
Claude Code is a genuinely impressive tool. We’ve used Claude Code extensively ourselves.
However, Anthropic’s recent blog post about using Claude Code for COBOL understanding – that wiped $40 billion off IBM’s stock price – is not new information. There is no new COBOL product, no answer to the vast limitations of LLMs in understanding complex legacy applications, and no signs of a real focus on this incredibly difficult stage of modernization.
Swimm is an Application Understanding Platform devoted to being best-in-class for, what Anthropic correctly called out, is the most important part of re-imagining applications. Using our deep AI expertise, we’ve tested the state of the art from Claude Code to see how well it handles understanding.
Let’s dive into it.
We ran Claude Code and Swimm on the same cobol programs
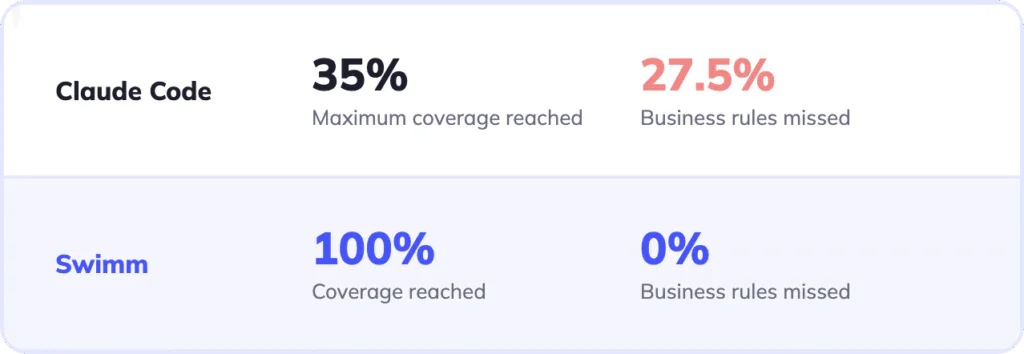
We ran Claude Code (Opus 4.6) and the Swimm platform on the same real COBOL programs looking for the actual analysis coverage depth and business rules extraction along with consistency and accuracy. We’ll get into the details but at a high level:
Coverage
Claude’s coverage ranged from 24-35% of the program across multiple attempts on the same task. There was no consistency between identical runs – results varied by up to 42%.
Swimm’s coverage was always 100%.
Business rules
With low coverage, it isn’t surprising that Claude completely missed 27.5% of business rules. However, potentially more concerning is the number of wrong or incomplete business rules it surfaced.
Swimm surfaced 100% of the business rules with 100% accuracy.
Modernization means getting every rule right – not some of them, some of the time
When an enterprise migrates a mainframe application to a modern platform, the goal isn’t to reproduce most of what the old system did in a pretty similar manner; it’s to reproduce all of it, exactly – including the edge cases, the conditional logic, and the calculations that determine whether a payment is correct or a claim is approved.
This sets three requirements for any tool used to extract business rules from legacy code:
- Complete coverage. Every business rule, every conditional branch, every algorithm must be captured. A rule that isn’t documented can’t be migrated. A paragraph that’s mentioned but not meaningfully described will not be transformed correctly.
- High accuracy. Conditions, constants, and logic must be exact. If a payment rule says “apply this rate when units > 0” and the extracted version drops the condition, the migrated system will apply the rate to zero-unit claims too. Nobody will know until an audit surfaces it.
- Consistency. The same source code should produce the same analysis every time it’s run. If two independent extractions of the same program return materially different results, there’s no reliable baseline to build a migration on.
In regulated industries, these aren’t just technical requirements. An inaccurate business rule extraction doesn’t produce a defect report – it produces a gap between what the modernized system does and what it’s legally required to do. In banking, that can mean capital calculation errors with regulatory consequences. In healthcare, it can mean incorrect Medicare billing under the False Claims Act, with civil penalties and personal liability for the executives who approved the migration.
Diving into the tests
We tested Claude Code (Opus 4.6) and Swimm’s deterministic platform on two real (and publicly available) CMS Medicare COBOL programs. These are government programs used to calculate Medicare payments; CMS released COBOL source code for its Pricer applications until January 2022, when it completed conversion to Java. The COBOL versions we used are available in the CMS PC Pricer historical archive.
- HOSPR210 – the Hospice PPS Pricer, which calculates payments for hospice claims (4,692 lines of code)
- OPPSCAL – the Outpatient PPS Pricer, which calculates payments for outpatient claims (18,835 lines of code)
While these programs are small compared to the multi-million lines of code codebases we help customers with, the Anthropic blog did suggest starting with small, clearly defined slices of the application to help it get the best results.
These programs are representative of real enterprise COBOL. They contain some complex control flow, GO TO statements that jump between sections non-linearly, copybooks with rate tables and wage index calculations, and business logic layered across fiscal years. They are not toy examples written to illustrate concepts. They are the kind of programs that actually run in enterprise environments.
We also explicitly removed the extensive inline documentation included in the open-source version. Real enterprise COBOL doesn’t come with explanations attached. These shouldn’t either. We did not further alter the programs in any way.
We ran Claude Code using Opus 4.6 three times on each program – independently, with no shared context between runs. We used a refined ~800-word extraction prompt with a 4-pass agentic strategy specifically designed for COBOL business rule extraction. This is not a naive test, and Claude Code used ~70 tools per run.
Swimm processed the same source files through its standard deterministic analysis engine. No tuning or further refinement was used.
We then compared the results across three dimensions: coverage, accuracy, and consistency.
What we found
Coverage: Entire subsystems were missed
Across three runs, Claude mentioned 69-86% of paragraphs on the smaller program and 24-35% on the larger one.
Before interpreting those numbers, it’s important to understand what they measure – and what they don’t. “Paragraphs mentioned in output” means the paragraph name appeared somewhere in the extracted documentation (both tools need to mention the paragraph a corresponding rule is taken from). A script that checked whether each paragraph name appeared in a text file could produce this metric. It’s the most easily quantifiable measure of coverage – and it’s the most generous one.
|
Claude (4.7K lines) |
Claude (18.8K lines) |
Swimm |
|
|---|---|---|---|
|
Paragraphs mentioned in output |
69–86% |
24–35% |
100% |
|
Missing rules (est.) |
~30–90 |
~300–350 |
0 |
|
Variance between runs |
12% |
42% |
0 |
Real coverage has three dimensions, and paragraph mentions only address the first. When a vendor claims high coverage, these are the three questions to ask:
- Paragraph reachability: Is the paragraph mentioned at all? Note that only paragraphs that are reached from the program’s entry point should be listed, and not “dead” paragraphs that are not reachable.
- Rule completeness: Are the business rules inside that paragraph fully extracted, or are multi-step algorithms compressed into a single vague sentence that conveys nothing usable?
- Execution context: Is it captured how and when the paragraph actually runs? In COBOL, a paragraph can be reached in multiple ways – called normally, jumped to via GO TO, or entered as part of a range. A paragraph reached via GO TO executes with a different call path and often conditionally. Documenting a paragraph without capturing that context often means documenting the wrong behavior.
Many paragraphs in Claude’s output satisfied only the first dimension. They appeared in the extraction, but the description was too vague to reconstruct how the program actually behaves.
On the larger program, the coverage problem was more severe: the main payment calculation paragraph – 70 lines of code that determines whether a claim gets paid, caps the patient’s coinsurance, and handles claim reversals – had zero extracted rules across all three runs. That subsystem simply isn’t there.
70 lines of code that determines whether a claim gets paid, caps the patient’s coinsurance, and handles claim reversals – had zero extracted rules
Accuracy: what “covered” can hide
We audited 280 business rules from the best Claude run on the smaller program in addition to all the Swimm business rules found. Swimm produced zero quality issues. Claude was a different story.
Here are some of the problems that we found in Claude’s output:
20 rules had meaningless descriptions. One paragraph was described as “Sum, move, zero.” That names the category of operations performed – arithmetic, data movement, reset – but without the source code in hand, there is no way to know from this description what is being summed, what is being moved, or what is being reset.
7 rules were misattributed. One run placed output field descriptions at the wrong program scope; another stated that a feature was introduced in FY2016. It was introduced in FY2019. A developer using this output to locate the relevant code would look in the wrong year section.
11 rules had dropped conditions. The clearest example: 11 CHC payment rules omit the condition UNITS2 > 0.
Consider this code segment:
“`
140600 IF BILL-REV2 = ‘0652’
140700 IF BILL-UNITS2 > 0
140800 IF BILL-UNITS2 < 32
140900 COMPUTE WRK-PAY-RATE2 ROUNDED =
141000 ((98.19 * BILL-BENE-WAGE-INDEX) + 44.72)
“`
Claude Code described this computation as happening when BILL-REV=2 and BILL-UNITS2<32.
The extracted version implies the payment applies to any claim. The actual rule only applies when the claim has units. A migration built on this extraction would produce overpayments on zero-unit claims – systematically, on every affected claim, until the error was discovered.
Here is another concrete example from the larger program. Consider this code:
“`
SEARCH W-PTCA-DAY-ENTRY VARYING W-PTCA-DAY-INDX
AT END
PERFORM 13130-ADD-ENTRY
THRU 13130-ADD-ENTRY-EXIT
WHEN W-PTCA-DAY-LIDOS (W-PTCA-DAY-INDX) = H-PTCA-LIDOS
PERFORM 13130-UPDATE-ENTRY
THRU 13130-UPDATE-ENTRY-EXIT.
“`
Claude extracted this rule for a PTCA processing paragraph:
If PTCA line flag is set → Set claim flag, load PTCA day table
What the code actually does:
For each PTCA line, search the PTCA day table for the line’s date of service. If not found (AT END), create a new day entry for that date. If found, update the existing entry for that day.
These are not close. The first description implies a flag check and a table load. The actual logic is an iterative table search with two separate outcomes depending on whether a matching date exists. A migration based on the extracted version would fail on any claim with multiple PTCA lines on different service dates – and produce wrong results silently.
Consistency: a higher rule count is not a quality signal
Across three runs on the larger program, the number of business rules extracted ranged from 140 to 226 on the same source code – a 42% spread. On the smaller program, the spread was 12%. Swimm’s deterministic approach produces the same output every time the same source files are analyzed.
The consistency problem compounds the accuracy problem in a specific way. The run that produced the most rules also produced the most errors – nine wrong regulatory dollar amounts embedded in Medicare pricing logic:
| Constant | Correct value | Value in highest-rule run |
|---|---|---|
| FY2016 IP Limit | $1,288 | $1,300 |
| FY2017 IP Limit | $1,316 | $1,340 |
| FY2015 Outlier Threshold | $2,775 | $2,900 |
| FY2017 Outlier Threshold | $3,825 | $3,325 |
These are not rounding errors. They are plausible-looking numbers that a reviewer might not catch without checking the source code directly. They would pass a human review of the extraction output. There is no metric in the extraction output itself that signals which run to trust.
This is an architectural problem – “we’ll validate it” is not a solution
The natural responses to these findings are: improve the prompt, or validate the extraction output against source code before migrating. Neither addresses the root problem.
On prompt improvement: the extraction prompt in these tests was approximately 800 words of structured instructions, refined across multiple iterations, with explicit guidance to cover every paragraph, cite source lines, and produce output in seven required sections. The gaps appeared anyway. Better prompting cannot fix a structural limitation.
The structural limitation is this: an LLM agent reads a codebase in passes, each informed by what it found previously. At each step, it decides what to read next based on what it already knows. There is no mechanism that guarantees every paragraph gets visited, that live execution paths are distinguished from dead code, or that the same decisions are made in the same order across independent runs. A model that navigates a codebase cannot know what it hasn’t seen. When you apply a probabilistic machine to a problem with a single correct solution (like an execution path based on the source code), you are liable to end up with mistakes. In COBOL, the problem is much harder than in other programming languages – as there are more than 300 dialects, and the LLM has inevitably not been trained on all of them.
On validation against source: systematic validation has two problems that compound each other. First, you cannot audit what you don’t know is missing. The main payment calculation paragraph on OPPSCAL (the larger program) produced zero rules in all three runs – a reviewer checking the output would have no indication that an entire 70-line subsystem was absent. Second, when three runs of the same extraction return 140, 199, and 226 rules respectively, there is no stable baseline to validate against. Determining which version is correct requires going back to the source code – which is exactly the manual work the extraction was supposed to replace.
A parser operating on the program’s full structure doesn’t have these problems. It processes the complete codebase by construction, not by navigation. Coverage is structural, not probabilistic.
Understanding is more than AI, it needs workflows
Anthropic highlights the essential nature of humans in the loop for the understanding phase of modernization. Yet, Claude Code does not actually have a dedicated way of supporting humans.
Hundreds of pages of documents in markdown is not an organization process.
Swimm’s platform, for example, creates easy navigation, fast validation paths, and workflows for adding organizational context. And the same information that teams align on is provided to AI for context, giving teams governance structures and guardrails. Context provided to AI is curated and exact to the business needs – reducing drift, cost, time, and ultimately risk.
What enterprise modernization actually requires
These findings aren’t an argument against AI for legacy code work. Claude Code is genuinely useful for developer productivity in many contexts.
Modernization is not that context. A migration that carries dropped conditions, compressed algorithms, or wrong regulatory constants will produce incorrect behavior in production. For enterprises in banking, healthcare, or insurance, the consequences extend well beyond a defect ticket.
What mainframe modernization requires is analysis that doesn’t provide best-effort understanding. It requires deterministic accuracy.
Swimm’s business rule extraction is built on deterministic static analysis of the full program AST: every paragraph covered by construction, every execution path traced, every result reproducible. Swimm expands copybooks recursively, traces memory across REDEFINE statements, traces path execution through convoluted GO TO, PERFORM and fallthrough chains, tracks variable values across multiple reassignments, and essentially – deeply “understands” COBOL. With Swimm, generative AI is used to translate those findings into human-readable form – it doesn’t infer them.
The COBOL versions of these programs are available in the CMS PC Pricer historical archive. Before committing to an approach for a real modernization program, running your actual COBOL through both a deterministic and an LLM-based extraction – and comparing the results – is a reasonable way to evaluate the gap for yourself.
