Traditionally, developers gain knowledge gradually when working on projects over time. I’m not referring to general knowledge such as a programming language. Instead, I am referring to project-specific knowledge, including the many decisions made while planning a project. This includes product decisions (what to implement, what not to implement, and why) and design decisions (what architecture to use, how to split the system into its components, and how the components interact).
There is, of course, more specific knowledge that accumulates either when developing code or reading it to understand something – for example, during debugging. Knowledge about how the code is constructed, what parts are essential, and how the data flows in the system is gradually accumulated.
Gradually is key here because in the mind of the developers as they develop their system, this knowledge is an inseparable part of the craft of programming.
Not surprisingly, this knowledge is hard to transfer. For example, when new developers join the team, they need to quickly learn all kinds of things from the design decisions through the specific implementation details; when a bug occurs, we need to find the cause and make a fix; when performing a code review or basically whenever we interact with code we haven’t written ourselves, we need to get into the mind of the developer who originally has originally written the code.
Our existing methods for sharing knowledge about software are fundamentally broken, and we need to prioritize sharing this knowledge efficiently and effectively. In this post, I will explain why and what can be done about it.
Why knowledge sharing methods are broken
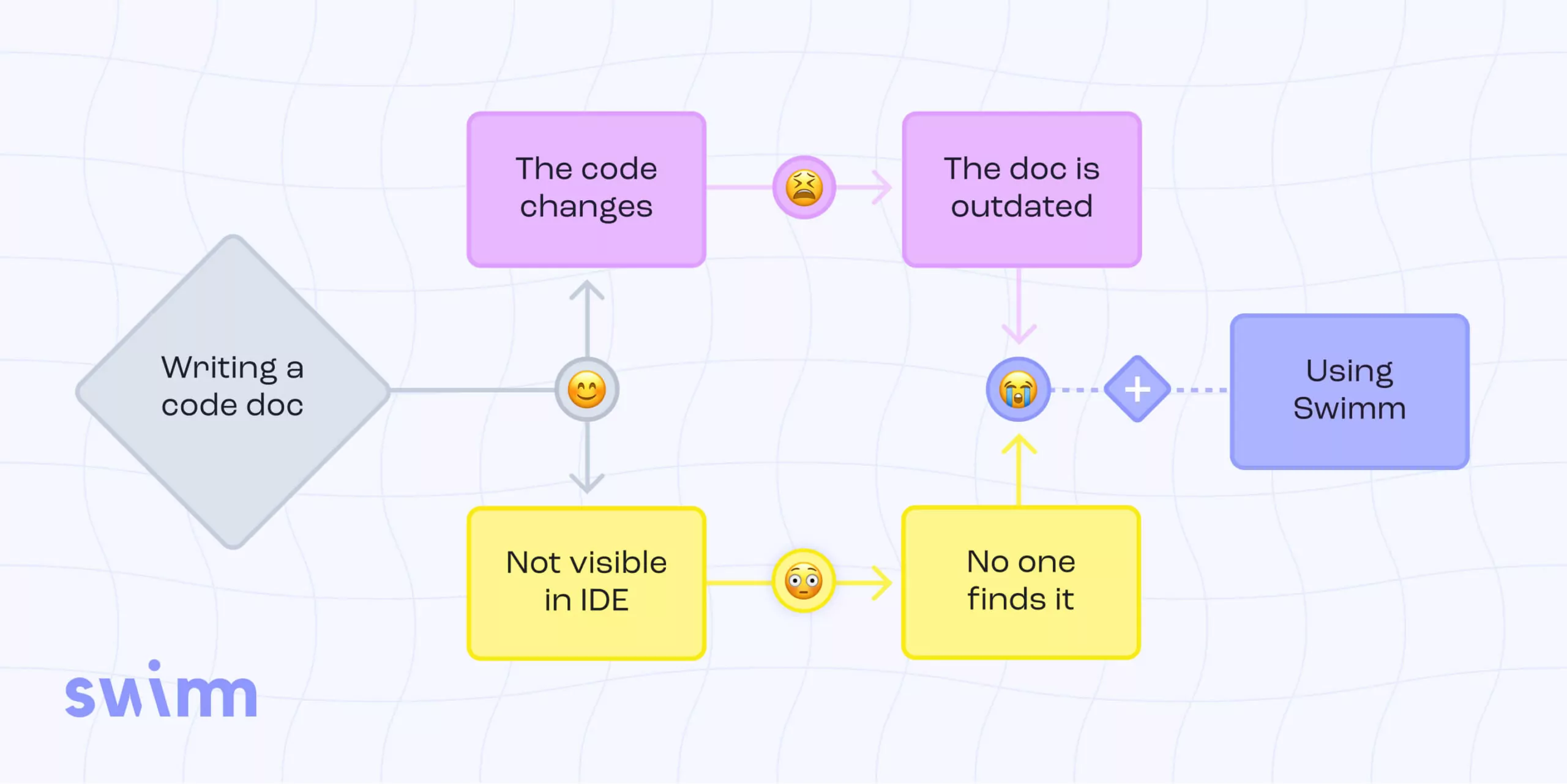
Knowledge sharing methods are broken for two fundamental reasons: knowledge is scattered, and documentation is outdated.
Knowledge is scattered
Where is that “knowledge” we want to transfer stored? Well, in the mind of the developers, of course. But then, when it is transferred, it is also stored somewhere. Some knowledge is found within the code itself, and some isn’t. Design decisions, for example, are hard to deduce from the code. Furthermore, in the code itself, you can’t find the reasons that made the developers not implement things in a certain way.
Knowledge about code can be transferred in oral conversations and, in this instance, not stored at all. They can be conveyed on recorded video calls, documents stored on shared folders or Wiki pages, code comments, README files, Slack conversations, emails, and more.
This scattered knowledge makes it extremely hard to find; most of the time, you don’t even know where to look for it – assuming there is any relevant documentation to begin with.
Documentation is outdated
Even when the relevant knowledge is documented, it is often outdated. This is the result of the nature of software; it quickly evolves. As developers create new features and fix bugs, the code constantly changes, and they simply don’t remember to update the relevant documentation or bother looking for it.
Time is always of the essence and locating and updating the documentation takes precious time that could be devoted to writing more code.
Developers no longer trust documentation
It’s a vicious cycle: when developers stumble on a document, they often lose trust in the documentation. Because once you find outdated documentation more than a couple of times, you are likely to assume that it’s probable that other docs are outdated as well.
So why would you, as a developer, bother to read the documentation? And of course, if it’s not valuable to read the documentation, it’s understandable why developers would not justify or prioritize the effort of writing the docs in the first place.
As a result, developers spend less time creating high-quality documentation, leading to other developers reading the documentation and not getting value from it, which leads to a stronger belief that there is no value in writing documentation at all.
Sometimes, developers try to avoid the problem of outdated documentation in advance – by writing only high-level documents describing general flows and architecture, as these are not liable to change frequently. However, this leaves many gaps. A lot of the important knowledge that simply cannot be covered by high-level documents is never documented.
Knowledge should be found and consumed at the right time
Even if we assume that all knowledge relevant to a software project exists in some written form and is centralized in a single place, it is not practical to just read all the relevant documentation once you join a new project. When, for example, should you read each document, and do you know when it’s the right time?
Swimm’s knowledge management solution
With Swimm, information is located and consumed in two forms.
- Developers get a high-level overview of the project they enter upon entrance using our Swimm Playlists.
- Using Swimm’s IDE plugins, developers find the relevant information just in time, when they need it, when trying to understand a part of the code that has relevant documentation, or when writing code where existing documentation can facilitate.
Swimm analyzes the changes introduced to the code on every PR. When the changes are minor, we Auto-sync them, track the relevant code parts, and update the documentation accordingly. When breaking changes are introduced, we mark them for the developer to manually update the documentation as part of the PR – when the information is fresh – as the breaking change has just been introduced.
Knowledge sharing is transforming teams
Knowledge sharing is transforming for developer teams with the use of code-coupled documentation. Learn more about Swimm’s knowledge management documentation platform and join our growing Swimm community on Slack around the world.
