
Some context
The Swimm Editor enables developers to create truly useful technical documentation. It’s a central, and arguably, one of the most important parts of the platform.
If you’re new here, Swimm is a devtool that makes all code easy to understand. And one of the ways we do that is through technical documentation. One of the features of the editor is the Snippet Studio, that allows developers to integrate code snippets from various repositories, which remain automatically updated even as the code evolves.
We do a lot of other things too, like AI documentation generation and legacy code modernization, but for the purpose of our story today, we’re going back to basics.
The problem
When I first joined Swimm, I was confronted with a challenging editor notorious for its bugs. It was a tough nut to crack, and nobody wanted to deal with it.

Issues kept popping up, users were getting frustrated, and it seemed like every fix led us further down a maintenance rabbit hole.

But didn’t you write tests?
You might think that tests are designed to prevent fixing one issue from breaking something else, and you’d be right. However, we quickly realized that the situation was far more complex than simple testing could handle.
Even though we had thorough manual and automated testing systems, they failed to prevent additional problems. We tested each system separately: our editor appeared robust on its own, and translating documents into MD files relied on well-tested but not fully MD-compatible legacy code, which seemed stable due to extensive use.
We used the same process for converting MD files back into the editor format. But when transitioning between these systems, everything failed. We were at a standstill, staring at process black boxes when moving between the parts – unable to lift up the hood and tackle the issues directly.
This also meant that more and more dev time was going towards reproducing issues encountered by users yet we consistently struggled to find a sustainable fix.
A turning point
Despite the slightly depressing overture, this is not a post about hardships! This is a post about turning things around.
That’s when we started rebuilding our process from the ground up, transforming our approach into a precise, targeted strategy.
From:

To:

Please learn from our mistakes
Building a solid development framework and dedicating time to develop the right tools to support it is crucial.
In this post I’ll share:
- A practical approach to maintaining complex systems
- A devtool first development process
- Some “funny” anecdotes about developing for Markdown
Changing your approach
The first step we took was rather drastic. We halted bug fixes in order to reevaluate our methods and identify key failings in our approach. We came up with 3 main points:
- Tunnel Vision: We focused too narrowly on specific bugs without considering systemic impacts.
- Overlooking regressions: Fixes for cross-process bugs failed to prevent their recurrence.
- Testing like a user: Manual, repetitive testing consumed excessive time without addressing underlying system issues.
Tunnel vision
To make good choices, you need to make sense of the complexity of your environment.
A.G. Lafley
The dev team at Swimm is made up of pure professionals. They investigate an issue and won’t stop until they’re sure they found the exact place where the process broke. And then they fix that break.
But that meant we were stuck in a cycle of fixing individual bugs and didn’t think much about how these bugs related to our system as a whole. Complex systems tend to have inter-dependencies, so when changes happen to one part of the system, other parts are at risk.
Even though we were testing and confirming that bugs were being fixed, we overlooked the potential chain reactions in the system, which led to the emergence of new, more significant issues.
Over looking regressions
Nature is great at hedging investments. Nature doesn’t hedge by betting for and against the same things. Nature hedges by cultivating resilience.
Hendrith Smith
As bugs became increasingly complex, we no longer had the right tools to keep regressions from creeping back in. Cross-process bugs were fixed, but we had no way of validating that they stayed that way.
Spoiler alert: they didn’t.
Testing like a user
Tools amplify your talent. The better your tools, and the better you know how to use them, the more productive you can be.
Andrew Hunt
We were dealing with bugs that spanned multiple system processes. And we worked them as such.
Manually.
Over and over again.

Unfortunately this meant that we were spending valuable time on reproduction, setting up environments to replicate bugs and then validate our solutions. This was time we could have spent actually solving problems.
Getting it right
It was crucial that we streamlined the way we worked on bugs. We removed all dependencies on external integrations which allowed us to focus only on the issues at hand.
We built a lab
We created a lab environment consolidating all of Swimm’s key processes into a single, integrated platform. The lab allowed us to isolate and address issues more effectively.
Initially, the setup included numerous components like an editor, commits, git providers, and pull requests, which seemed overwhelming. But once we broke it down, we identified three core components:
- WYSIWYG editor
- MD to JSON parser
- JSON to MD serializer
We transformed these components into standalone, encapsulated services. This reorganization allowed us to develop a unified app that facilitates seamless navigation among our services. Now we were able to cruise through all parts of our process by simply moving from one tab to the next.
This seemingly simple tool dramatically reduced the time it took to handle a test case—from well over a minute per case down to an instant, eliminating previous obstacles encountered during issue resolution.
Before:
After:

Making progress
Now that we were saving time debugging, reproducing, and validating our solutions we were able to seamlessly navigate throughout our product lifecycle, inspecting each part in depth.
With all that free time on our hands, now we could tackle the real issues.
Addressing asymmetry
While building the editor, we consistently encountered issues with asymmetric transformations. Essentially, users would create a document, save it, then reload it only to find the content slightly altered from what they originally entered.
We realized that it boiled down to two serious HTML to Markdown issues:
- The whitespace problem
- HTML character entity ambiguity
The whitespace problem
Swimm’s editor is built as a WYSIWYG editor and Swimm’s documentation is saved as standard CommonMark files. And these tools address whitespace differently.
While users tend to use white spaces for formatting documents in a WYSIWYG editor, Markdown files tend, on a whole, to completely ignore them. So tabs, indentation, and visual whitespaces were all lost once our document was serialized as Markdown. This led to a deep rooted issue in our serialize <-> parse cycle.
We needed to fix and test this issue, making sure that:
- Users of the editor were always getting back what they put in
- Raw MD files remained CommonMark compatible and viewable in standard MD previewers
We reviewed a number of options (perhaps a subject for another post). And finally we came to the following solution:
Input:
Foo
BarConverter:
{
paragraph(state, node) {
if (node.childCount === 0) {
state.write(" ");
} else {
state.renderInline(node);
}
state.closeBlock(node);
},
}Output:
Foo
BarUsing a character representation of whitespace ( ) to replace the whitespaces we managed to strike the perfect balance between keeping MDs readable (most previewers ignore these all together) and keeping our users’ intentions intact.
And just like that – all was right in the world of whitespace.
HTML character entity ambiguity

Here we found ourselves facing the opposite issue. Our serialize <-> parse cycle moves documents between HTML syntax and CommonMark syntax, meaning that when a user would insert escaped HTML characters (for instance <) into the editor, it is clear that they meant to write down those escaped characters.
But when turning a corner and trying to parse those characters back, we received the actual HTML entity (< in our case).
This could also affect the document’s styling. Transforming a plain text phrase (ex. <b>Not Bold<b>) into a bold styled one (<b>Not Bold</b>), changing how the user intended the document to look.
Following another deep dive (perhaps post #3?), we landed at the following solution:
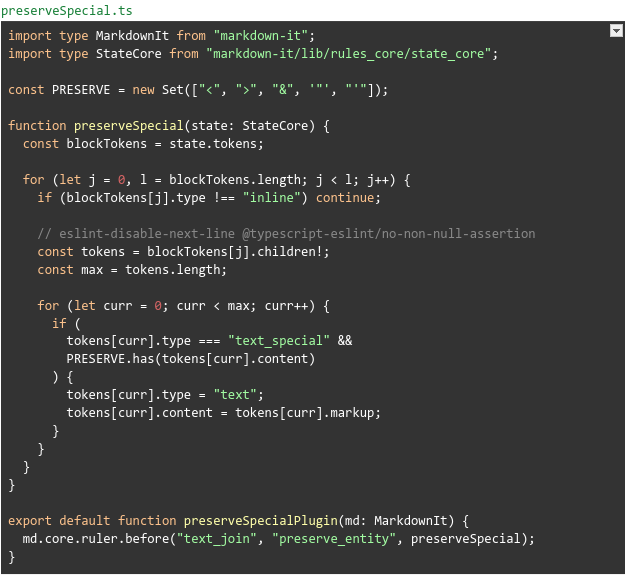
Which ended up looking like this:

Opting to preserve “troublesome” characters and avoid auto-unescaping them. After extensive testing, we confirmed that this approach consistently returned the exact output users intended.

How bad @$$ are we? 😏
But wait…
One final issue
We still needed to tackle regressions. Even though we had all of this incredible work in place, without an automatic and robust way to validate these behaviors end to end, we risked the next issue undoing all of the hard work we just did.
Every bug is a test case
Throughout the process, we treated every bug as a test case. We created unique tests for each, compiling a codex of all the issues we encountered. Using the lab infrastructure we built, we had the ability to create CI pipelines to run these test scenarios, validating every change to ensure that our work can never be undone.

Now we really cracked it.

Wrapping up
We began this journey after identifying 3 main issues in our development process:
- We forgot about our system
- We approached each bug separately
- We focused on at-the-break-point maintenance
- We overlooked regressions
- Our issues spanned multiple Swimm processes and services, and we did not have a way to properly test that they all fit well together
- We tested our specific solutions, but forgot to watch for system inter-dependencies
- We tested like users
- Developer time is one of the most valuable resources we have
- We spend a lot of time going through our system following a test case.
So now that all is said and done, I’m excited to share some valuable lessons and takeaways:
Markdown is hard
But navigating between two syntaxes with different grammatical rule sets is even harder. When you find yourself faced with issues that are incredibly difficult to solve, sticking to lessons you’ve learned becomes even more valuable – it can literally save you from an endless cycle of work (and rework).
Build custom tools
Leveraging our unique perspective as developers, not end-users, allows us to peek into the “black boxes” of our systems. We’ve built tools to remove obstacles, isolate processes, and clarify issues, significantly changing our development practices and enhancing efficiency.
Build system resilience
By treating each encountered bug as a test case and maintaining a comprehensive database of resolved issues, we continuously test and retest. This practice helps us keep track of complex system interdependencies, ensuring the robustness of our system and enabling our team to tackle new challenges confidently.
So, want to see all of this in action?
Create your free account here and see the magic of the Swimm Editor for yourself.
