Large Language Models (LLMs) have emerged as powerful tools, adept at generating both natural language and code across various tasks. In particular, organizations are increasingly using AI Coding Assistants for coding tasks, including code completion, summarization, and generation.
While these AI tools excel at certain tasks, their effectiveness is limited by a lack of context. Trained on vast datasets of web-based language and code, they lack specific knowledge of your company’s codebase or the particular problem at hand. Context is crucial for these tools to function optimally.
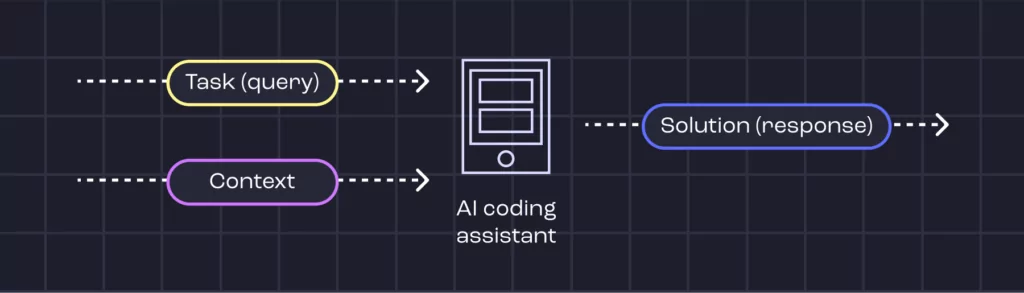
Users provide a task, and the AI assistant provides the context. Then, a LLM is used to generate the solution. Without context, the model is only able to use the “generic” knowledge it possesses, not any knowledge about the specific codebase.
AI coding assistants
No context
```python
def calculate_total_price(shopping_cart):
total_price = 0
for item in shopping_cart:
total_price += item.price
return total_price
```This function was generated by a model that lacks additional context. Here are a few of the obvious issues:
- Is the codebase written in Python? If not, the generated code is useless.
- Is `shopping_cart` really a list? What if it’s a dictionary? An object?
- Is `price` really an attribute of `item`?
- Are there edge cases that the model did not consider? For example, what happens if `price` is negative? Can this happen in the system?
When it comes to asking these questions, we don’t really know the answers unless we have the additional context. This is a simple example. But, in reality developers deal with complex codebases and without the much needed context, the model is far more likely to generate code that is not useful – perhaps even harmful – as it enables developers to rely on code that is simply not reliable.
Partial context
Say we ask our AI assistant to implement the same function, but this time we provide it with partial context. We tell our AI assistant that the codebase is written in Typescript, and that `shopping_cart` is an object with the attributes `name`, `price` and `discount`. The model might generate the following code:
```typescript
function calculate_total_price(shopping_cart: { name: string, price: number, discount: number }): number {
let total_price = 0;
for (const item of shopping_cart) {
total_price += item.price * (1 - item.discount);
}
return total_price;
}
```Much better! The generated code is now in Typescript, and it is more likely to be correct. However, there are still some issues:
- The model assumed the discount is a number between 0 and 1, but it could be an absolute number, a percentage, or a boolean that indicates whether the item is discounted or not, or a string indicating the discount type, or even a function that calculates the discount.
- Again, there might be edge cases or other constraints the model hasn’t taken into account.
So the tl;dr here? The accuracy and utility of code generated by AI assistants are directly proportional to the amount and quality of context provided.
Notice that we assume a human developer is still in the loop to verify the code. This is very important when partial context is given because the model may output code that has the “look and feel” of your codebase, but is still incorrect and chances are it lacks insight into important edge cases.
GIGO: Gold in, gold out
The previous examples show that the quality of the generated code is highly dependent on the context. The more context we provide, the better the generated code will be. However, this is not always the case. If we provide the model with incorrect context, the generated code is likely to be incorrect as well.
This brings us to the GIGO principle: ‘Garbage In, Garbage Out.’ However, I prefer to think of it as ‘Gold In, Gold Out’ to emphasize the importance of quality input.
For example, if we provide the model with context that uses the shopping cart in the correct way, the model is likely to generate code that uses the shopping cart in the correct way as well.
So the challenge is not only to provide the model with context, but to provide it with correct context.
Conclusion
In this post, we discussed the importance of context for AI Coding Assistants and that the quality of the generated code is highly dependent on the context. The more context provided, the better the generated code is likely to be. However, if we provide the model with incorrect context, the generated code or answers are likely to be incorrect as well. Ultimately, the key to harnessing the full potential of AI Coding Assistants lies in providing accurate and relevant context, ensuring that the solutions they generate are both practical and reliable.
We have an exciting launch coming soon. Sign up here to learn more and be the first to know.
