What Are Large Language Models (LLM)?
Large Language Models (LLM) are a type of machine learning model designed to understand and generate human-like text. They are trained on a vast corpus of text data, allowing them to learn the complex patterns and structures inherent in human language. This ability to comprehend and replicate human language makes them a powerful tool in a variety of fields, from natural language processing to AI-driven content generation.
LLMs can be thought of as an extension of traditional language models, which work on a smaller scale. However, the ‘large’ in Large Language Models refers not just to their size, but also to their capacity for understanding and generating text. They are capable of working with longer sequences of text, and have a deeper understanding of the nuances of language, including context, sentiment, and even humor.
LLMs are a significant development in the field of AI and machine learning. Their ability to understand and mimic human language is a testament to the progress we’ve made in these fields. But to truly appreciate their power and potential, we need to delve into the mechanics of how they work.
Related content: Read our guide to embeddings machine learning
This is part of an extensive series of guides about AI technology.
Types of Large Language Models
Let’s review the primary architectures used to create LLMs, from early patterns to the latest, transformer-based architectures.
Related content: Read our guide to zero shot learning
Sequence-to-Sequence Model
Sequence-to-sequence models, also known as Seq2Seq models, are a type of large language model that convert sequences from one domain to sequences in another domain. This makes them ideal for tasks like machine translation, speech recognition, and text summarization.
Seq2Seq models consist of two main components, the encoder and the decoder. They work in tandem to process the input and generate the output. The encoder maps the input sequence to a fixed-length vector, and the decoder generates the output sequence from this vector.
Recursive Neural Network Models
Recursive Neural Network models, also known as RNNs, are a type of large language models that process data structures in a hierarchical manner. They are particularly useful for tasks that involve understanding the structure of sentences, like sentiment analysis and semantic parsing.
Unlike other neural network models that process input data in a sequential manner, RNNs process it in a tree-like structure, making them capable of capturing the hierarchical nature of languages.
Autoencoder-Based Model
Autoencoder-based models are a type of large language models that use an encoding-decoding mechanism. The encoder takes the input data and compresses it into a lower-dimensional representation. The decoder then uses this representation to reconstruct the original data.
These models are particularly useful for tasks like anomaly detection, denoising, and dimensionality reduction. For example, they can be used in text generation to generate sentences that are similar to those in the training data but are not exact copies. This makes autoencoder-based models an excellent tool for creative writing and paraphrasing tasks.
Transformer-Based Models
Transformer-based models are a type of large language models that use a mechanism called attention to understand the context of words in a sentence. This mechanism allows the model to focus on different parts of the input when generating the output.
Transformer-based models have been successful in various NLP tasks, including translation, summarization, and sentiment analysis. They are also the backbone of popular models like BERT (Bidirectional Encoder Representations from Transformers), OpenAI’s family of GPT models (powering the popular ChatGPT and Microsoft Bing), and Google’s PaLM (powering Google Bard).
Related content: Read our guide to transformer neural networks
How Transformer-Based LLMs Large Language Models Work: Key Components
LLMs are complex systems. We’ll review their main components to understand their inner workings a bit better. Our discussion will focus on transformer-based LLMs, which are currently the state of the art.
Word Embedding
Creating a large language model hinges on the initial step of word embedding. It’s all about translating words into vectors within a multi-dimensional plane, with closely related words being grouped. This aids the model in deciphering word definitions and making assumptions based on that comprehension.
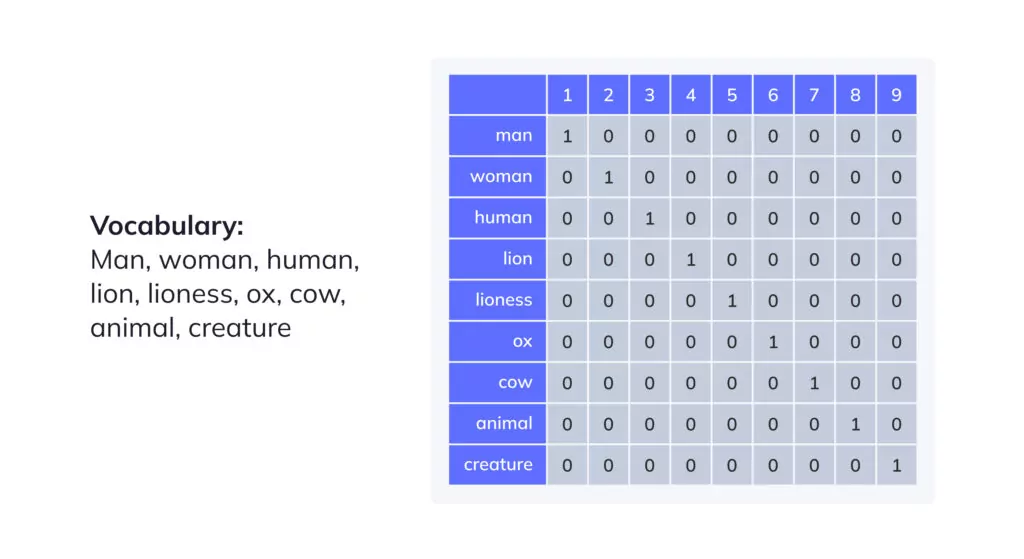
For example, consider the words “ox” and “cow”. Typically, these words will be situated closer to one another, compared to a different word pair such as “ox” and “plant”. These words are similar in that they represent farm animals. In the context of word embedding, these words would be depicted as vectors in proximity to each other within the vector space. This helps the model understand that these terms share likeness in their meanings and can be used interchangeably in various contexts.
The formulation of word embeddings requires training a neural network on a vast volume of text data, relevant to the inputs and outputs the model is expected to handle. Throughout the training phase, the network tries to predict the odds of a word’s occurrence within a specific context, reliant on the surrounding words in a given sentence. The vectors generated through this procedure encapsulate the semantic associations between words within the text corpus.
The following image shows how words that are similar in meaning will be represented as “nearby” in the resulting word embeddings.
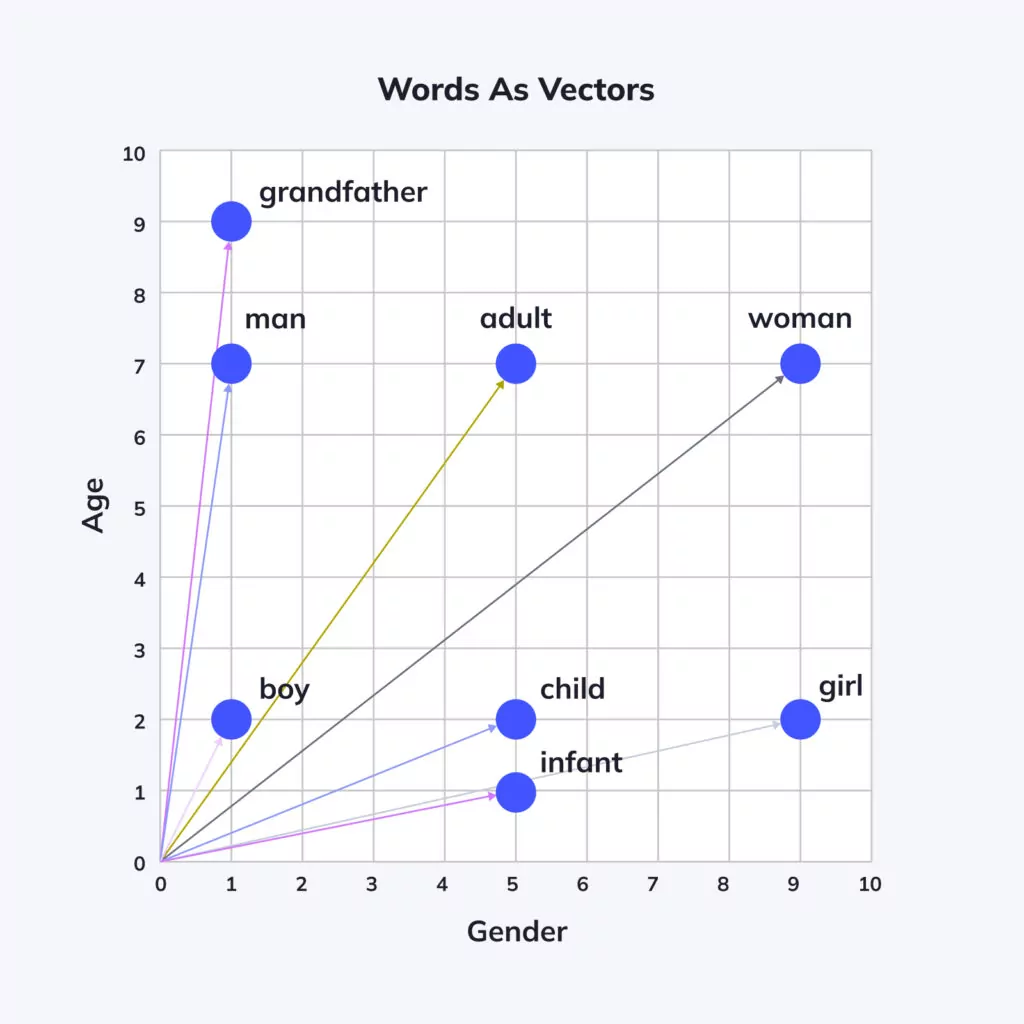
Upon their formation, word embeddings can serve as inputs for a broader neural network, aiming at a particular language-related task like text classification or machine translation. Utilizing word embeddings allows the model to grasp the essence of words and generate more precise predictions based on that comprehension.
Positional Encoding
Positional encoding is the model’s method for determining the order of words in a sequence. Unlike word embedding, it doesn’t deal with the semantics of words or their respective relationships (e.g., that “man” and “woman” are similar). Positional encoding focuses solely on tracking the sequence of words.
For instance, when interpreting the statement “The cow is in the field” into a different language, it’s crucial to remember that “cow” precedes “field.” Maintaining the correct word order is pivotal for tasks such as translation, content summarization, and question response.
During the training segment, the neural network is exposed to an extensive corpus of textual data. Subsequently, it’s trained to base predictions on this data. The network’s neurons have their weights progressively modified, utilizing a backpropagation algorithm. This is done to reduce the mismatch between the anticipated output and the actual output.
Transformers
The transformer layer is an independent layer that goes into action after the standard neural network components described above.
The role of the transformer layer is to process the entire input sequence simultaneously rather than cumulatively. Its operation depends on two components: the self-attention mechanism and the feedforward neural network.
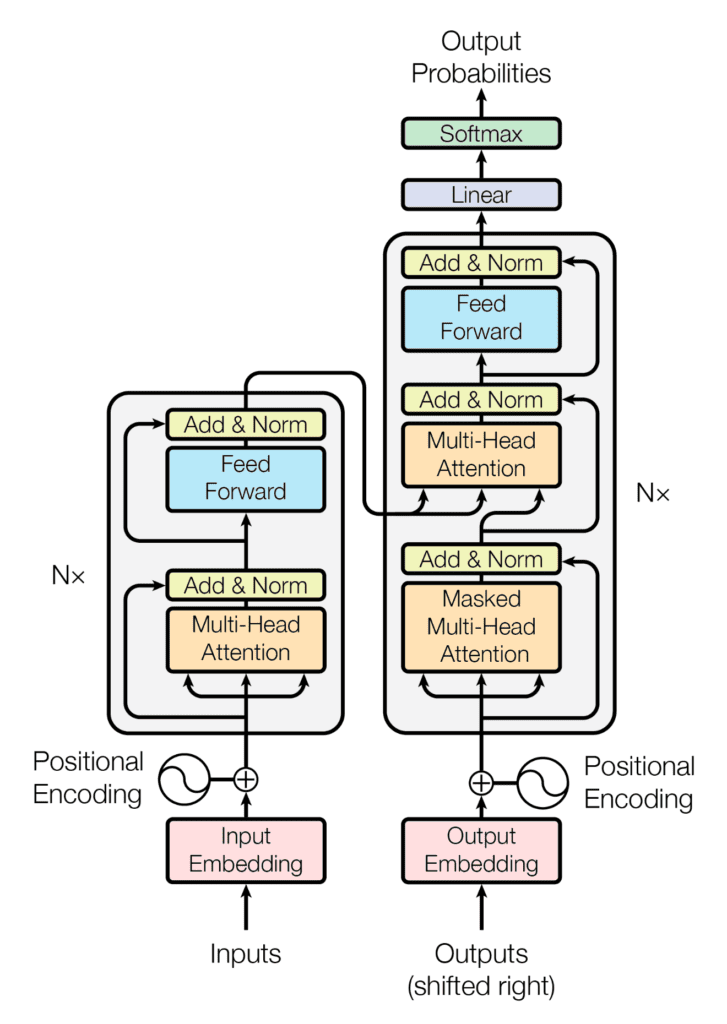
Source: ResearchGate
The self-attention mechanism enables the model to attribute a weight to each word in the sequence, based on its significance in the prediction. This allows the model to decode the relationships between terms, disregarding their relative positioning.
Once the sequence has been processed by the self-attention mechanism, it’s the turn of the position-wise feed-forward layer. Each position within the input sequence is processed individually by this layer.
For each specific position, a fully connected layer accepts a vector representation of the token (either a word or a sub-word) in that spot. The fully connected layers transform the input vector into new vector configurations. This transformation helps the model learn intricate patterns and relationships among words.
During the training phase, the backpropagation algorithm is employed, similar to other traditional neural network layers. This algorithm helps continually adjust the transformer layer’s weights to decrease divergence between the anticipated and actual outputs.
Text Generation
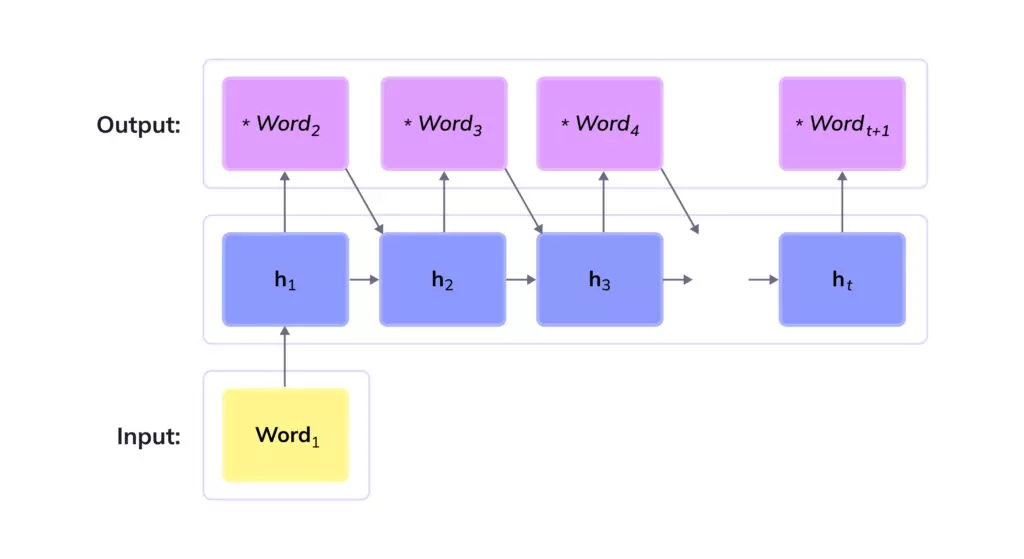
The final phase for most LLM systems is text generation. Once the model is appropriately trained and fine-tuned, it can generate text as an answer to a particular prompt or question. A common method involves priming the model with an input seed—this can range from a handful of words to an entire paragraph. The LLM then employs its learned patterns to craft a coherent reply pertinent to the context provided.
The process of text creation is based on an autoregressive technique. Here, the model constructs every single word or token in the output sequence individually, drawing on the preceding words it has generated. For the prediction of each subsequent word or token, the model utilizes the parameters it has accumulated throughout its training phase and calculates the anticipated probability distribution. The most probable option is then picked as the next part of the output.
Improving LLM Performance With Human-Guided Reinforcement Learning
A major breakthrough in the development of Large Language Models (LLMs) was the integration of Reinforcement Learning from Human Feedback (RLHF). This was a key technique behind GPT 3.5, the technology behind ChatGPT, which brought LLMs to the masses and quickly attained over 100 million users.
RLHF enables LLMs to learn and refine themselves using feedback received from humans. RLHF is an ongoing feedback loop facilitated by a human who is interacting with the machine learning model. The feedback from the human can either be explicit or could be inferred. Within the context of LLMs, this means that if the model delivers an incorrect response, the human user can fix the model’s response, helping the model improve its accuracy.
For instance, if an LLM creates content that lacks grammatical correctness or semantic relevance, or includes harmful or inappropriate elements, a human can provide valuable feedback to the LLM, pinpointing the good and bad portions of the generated text.
After this entire process—from word embeddings through to positional encoding, processing with transformers, text generation, and human-guided reinforcement learning—LLMs are able to generate surprisingly human-like responses to a wide range of prompts. This technology is the basis of the AI revolution that is set to transform the world.
Large Language Models vs. Generative AI: What Is the Difference?
Generative AI refers to a category of artificial intelligence models that are designed to generate new, previously unseen content. This content can range from text, images, videos, to audio and more. The primary attribute of generative AI models is their ability to create rather than simply analyze or categorize existing data. They can “imagine” and produce new pieces of content based on their training data.
LLMs fall under the umbrella of generative AI, making them a subset of this broader category. While all LLMs are generative AI models, not all generative AI models are LLMs. For instance, models designed to create images or music are generative AI but are not language models.
LLMs specifically focus on understanding and generating human-like text. Their training on vast amounts of textual data enables them to learn the intricacies and nuances of human language. By leveraging patterns they’ve detected in their training data, LLMs can generate coherent and contextually relevant text passages, sentences, or even entire articles.
In contrast, other forms of generative AI might be trained on visual data to generate new images or on audio data to produce new pieces of music. The underlying principle is similar: these models learn from their training data and then generate new content based on patterns they’ve recognized.
Large Language Model Use Cases
There are numerous use cases for LLMs, thanks to their unprecedented ability to understand and generate human-like text. While many more use cases are likely to emerge, as of the time of this writing, they include:
Information Retrieval
LLMs can be used in information retrieval systems to improve the accuracy and relevance of search results. They can understand the context and sentiment of the search query, allowing them to return results that are not just relevant, but also contextually appropriate and sentimentally accurate.
Sentiment Analysis
LLMs can be used in sentiment analysis to determine the sentiment of a piece of text. They can understand the nuances of language, including the context and the tone, allowing them to accurately determine the sentiment of the text.
Text Generation
LLMs can be used in text generation to create human-like text. They can generate text that’s both contextually relevant and sentimentally accurate, making them a powerful tool in fields like content generation and natural language processing.
Code Generation
LLMs can be used in code generation to create code that’s functional and efficient. They can understand the requirements of the code, and use this understanding to generate code in virtually any programming language that meets these requirements.
Chatbots and Conversational AI
LLMs can be used in chatbots and conversational AI to create bots that can understand and respond to human language. They can understand the context and sentiment of the conversation, allowing them to respond in a way that’s both contextually appropriate and sentimentally accurate.
Examples of Large Language Models
The following models have significantly contributed to the advancements in NLP and have set new benchmarks in numerous language tasks:
GPT
GPT, which stands for Generative Pretrained Transformer, is a large language model developed by OpenAI. The first version was released in 2018. It is trained on a diverse range of internet text and can generate coherent, contextually relevant sentences by predicting the next word in a given sequence of words. GPT-3, released in 2020, had 175 billion parameters and was the first model to produce highly convincing, human-like text and code based on nuanced instructions.
In late 2022, OpenAI released ChatGPT, based on GPT 3.5 and enhanced with RLHF. ChatGPT was revolutionary in its ability to generate human-like outputs based on natural language prompts. In April 2023, OpenAI released GPT-4, its most capable model, which is now available as part of the ChatGPT service and also directly via API. GPT-4 significantly surpasses the capabilities of GPT 3.5 in terms of the quality, accuracy, and contextual relevance of its outputs.
BERT
BERT, short for Bidirectional Encoder Representations from Transformers, is a model developed by Google. Unlike GPT which only considers the context to the left of a word, BERT looks at both sides. This bidirectional approach allows BERT to understand the context of a word better, thereby improving its performance in understanding and generating language. BERT has been a key player in various NLP tasks, including question answering and language inference. For several years it has been a core part of the Google Search engine.
LaMDA
LaMDA is a large language model developed by Google. It was an early model that was able to engage in open-ended conversations on any topic, including the ability to carry forward the context of a conversation, and consider information from previous exchanges. LaMDA was not released to the public, but captured the public’s imagination with its ability to interact with users in a human-like way.
A Google engineer named Blake Lemoine, who worked closely with LaMDA, believed the system was sentient. But his claim was disputed by Google itself and the most experts from the AI community.
Orca
Orca is an LLM developed by Microsoft, based on a variant of the Meta LLaMA model with 13 billion parameters. Its compact size makes it operational on a simple laptop. The Orca model is designed to surpass existing open-source models, replicating the logic processing methods used by traditional large language models. With far fewer parameters, Orca competes with the performance levels of GPT-4 and stands equal to GPT-3.5 in a variety of tasks.
PaLM
Google’s Pathways Language Model (PaLM) is a transformer-based model consisting of 540 billion parameters, powering its AI intelligence chatbot, Bard. This model, designed to perform reasoning tasks like coding, mathematics, classification, and question-response activities, is trained across numerous TPU 4 Pods, Google’s bespoke hardware for machine learning. The PaLM model is capable of breaking down complex tasks into more manageable subtasks.
The name PaLM originates from Google’s research project on Pathways, striving to build a master model catering to a wide range of applications. There are several precision-tuned iterations of PaLM. Med-PaLM 2 is tailored for life sciences and medical information, while Sec-PaLM is designed for cybersecurity implementation, aiding in expedited threat analysis.
5 Challenges of Large Language Models
While LLMs have shown remarkable potential, their development and deployment are not without challenges. These primarily revolve around the compute, cost, and time-intensive workloads, the scale of data required, and the technical expertise needed.
1. Output Quality and Hallucinations
One of the significant challenges faced when deploying LLMs is the quality of their outputs. Despite their advanced training and large size, LLMs are susceptible to generating outputs that may be factually incorrect or incoherent in specific contexts. These “hallucinations” can be misleading or even harmful in certain applications, such as misinformation spread, medical advice, or legal contexts.
2. AI Safety
The rapid development and deployment of LLMs raise major safety concerns:
- Propagation of bias: If an LLM is trained on biased data, it can replicate and even amplify those biases in its outputs. This poses severe ethical concerns, especially in applications that involve decision-making or influencing public opinion.
- Misuse and malicious intent: LLMs can be employed by malicious actors to spread misinformation, create fake news, or even for cyberattacks, making them potential tools for harm in the wrong hands.
- Over-reliance: An over-reliance on LLMs without human oversight can lead to misjudgments, especially in crucial areas like medicine, finance, and law, where the consequences of errors can be severe.
- Loss of accountability: It might become challenging to attribute responsibility when things go wrong, especially if decisions are made solely based on an LLM’s output.
- Emergence of artificial general intelligence (AGI): There is growing concern in the global community about the possible future development of LLMs, and the emergency of AGI (an AI that is equal or superior to human intelligence). This could have a major impact on human culture and even pose an existential risk to humanity.
3. Compute, Cost, and Time-Intensive Workloads
LLMs, given their size and complexity, require substantial computational resources for training. The training process involves passing through terabytes of data multiple times, which can take weeks or even months on powerful hardware setups. This results in high costs, both in terms of purchasing and maintaining the necessary infrastructure and the electricity bills for running these models.
4. Scale of Data Required
Another challenge is the sheer scale of data required to train these models. LLMs need vast amounts of diverse, high-quality text data to learn effectively. This not only presents a challenge in terms of data collection and preparation but also raises concerns about data privacy and the risk of the model learning and propagating biased or harmful content present in the training data.
5. Technical Expertise
The development and deployment of LLMs require a high level of technical expertise. Understanding the intricate workings of these models, tuning their hyperparameters for optimal performance, and managing the extensive computational resources they require is no mean feat. This often restricts the use of LLMs to a small group of researchers and organizations with the necessary skills and resources.
Conclusion
The advent of LLMs marks a significant stride in the realms of artificial intelligence and natural language processing. Their unprecedented capability to comprehend and replicate human-like text has opened doors to myriad applications, ranging from information retrieval to chatbots and code generation.
As with all groundbreaking innovations, LLMs bring forth their set of challenges. While the potential for misinformation, bias propagation, and the sheer computational demands they place are real concerns, they also present opportunities. These challenges beckon the scientific and technology communities to collaborate, innovate, and establish safeguards that ensure the ethical and responsible deployment of these models.
The future of LLMs promising. As we enter a new era of AI-powered communication, it’s essential to approach LLMs with both optimism and caution, remembering that while technology can replicate language, the responsibility to ensure its meaningful and positive application lies with humanity.
See Additional Guides on Key AI Technology Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of AI technology.
AI Cyber Security
Authored by Exabeam
- [Guide] AI Cyber Security: Securing AI Systems Against Cyber Threats
- [Guide] AI Regulations and LLM Regulations: Past, Present, and Future
- [Blog] Cybersecurity Threats: Everything you Need to Know
- [Product] Exabeam | AI-Driven Security Operations
Open Source AI
Authored by Instaclustr
- [Guide] Top 10 open source databases: Detailed feature comparison
- [Guide] Open source AI tools: Pros and cons, types, and top 10 projects
- [Blog] Multi Data Center Apache Spark™/Cassandra Benchmark
- [Product] NetApp Instaclustr Data Platform
Image Editing
Authored by Cloudinary
Adding Watermarks, Credits, Badges, and Text Overlays to Images