What Are Word Embeddings?
Word embeddings are a key concept in natural language processing (NLP), a field within machine learning. Word embeddings transform textual data, which machine learning algorithms can’t understand, into a numerical form they can comprehend. In addition, they can be used to capture the contextual essence of words, their semantic and syntactic similarity, and their relation with other words.
The concept of word embeddings is rooted in the idea that the semantics of a word can be represented in terms of its context. This idea is a departure from traditional bag-of-words models that represent each word as a unique entity, disregarding context and semantics. Word embeddings, on the other hand, transform words into vectors in a multi-dimensional space, where the spatial distance between words corresponds to their semantic or linguistic similarity.
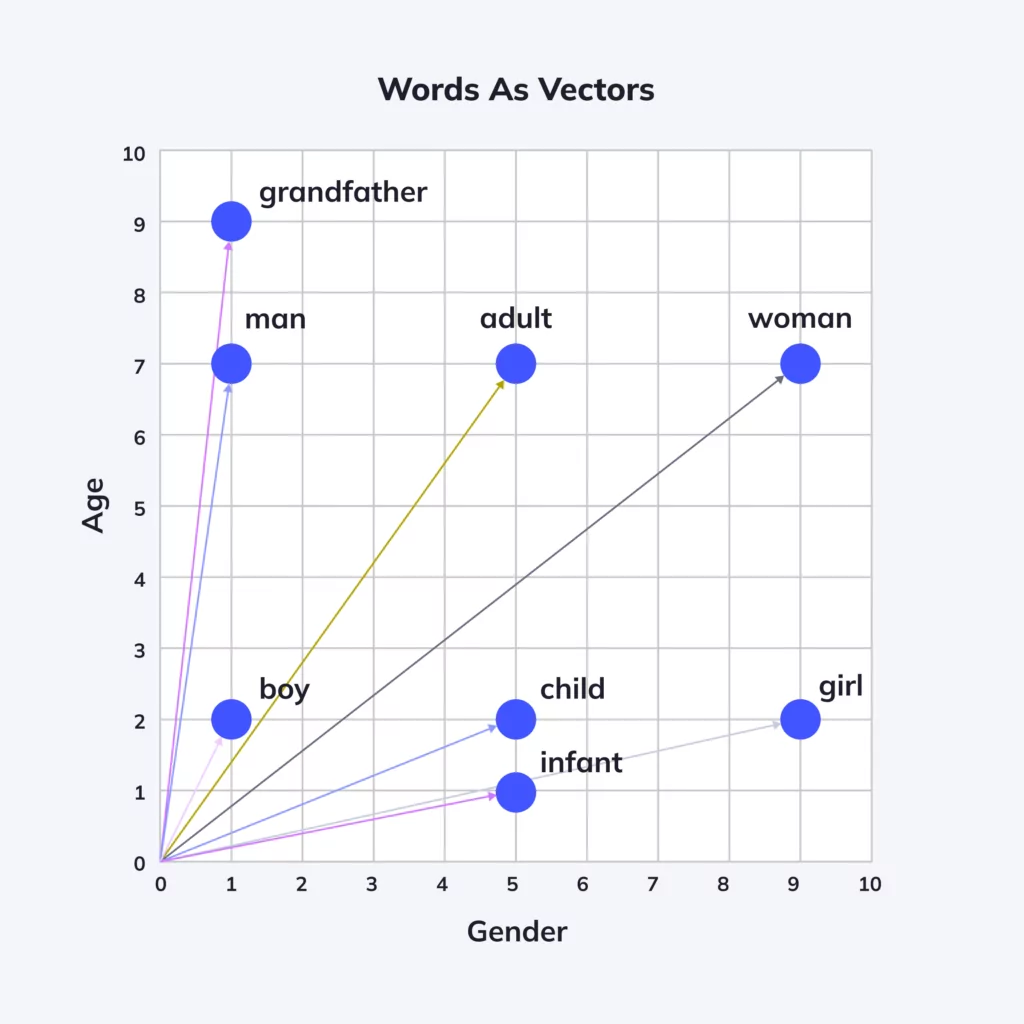
Why Are Word Embeddings Important?
Here are a few reasons word embeddings are benefits in machine learning and NLP:
- Capturing semantic meaning: Word embeddings allow us to quantify and categorize semantic similarities between linguistic items. They provide a rich representation of words where the semantics are embedded in the dimensions of the vector space, making it possible for algorithms to understand the relationships between words.
- Dimensionality reduction: In contrast to traditional bag-of-words models, where each unique word in the corpus is assigned a unique dimension, word embeddings map words into a lower-dimensional space where the dimensions represent semantic features. This makes word embeddings more computationally efficient.
- Handling large vocabularies: Traditional text representation techniques struggle in the face of vast vocabularies, due to the curse of dimensionality and sparsity issues. By representing words as dense vectors, word embeddings can handle large vocabularies efficiently.
- Enabling transfer learning: This is a machine learning technique where pre-trained models are used on a new, but related problem. Pre-trained word embeddings learned from large datasets can be leveraged to improve performance on smaller, related tasks. This can significantly reduce the effort of creating new NLP models.
Related content: Read our guide to embeddings machine learning
5 Types of Word Embedding Techniques
There two main categories of word embedding methods:
- Frequency-based embedding: Embedding methods that utilize the frequency of words to generate their vector representations. Frequency-based methods use statistical measures of how often words appear in the corpus to encode semantic information.
- Prediction-based embeddings: Generated by models that learn to predict words from their neighboring words in sentences. These methods aim to position words with similar contexts closely together in the embedding space. They often result in more nuanced word vectors that capture a wide array of linguistic relationships.
Modern NLP models, such as the Transformer architecture, typically use prediction-based embeddings.
Frequency-based Embeddings
1. Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF is a statistical measure used to evaluate the importance of a word to a document in a collection or corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus.
In the context of word embeddings, TF-IDF can be thought of as a very basic embedding technique, where words are represented as vectors of their TF-IDF scores across multiple documents. Despite its simplicity, TF-IDF can be effective in tasks such as information retrieval and text classification.
2. Co-occurrence Matrix
A co-occurrence matrix is a matrix that quantifies how often different words appear together in a corpus. In terms of word embeddings, each word is represented as a vector of its co-occurrence frequencies with other words.
This technique allows us to capture semantic relationships between words, as words that often appear together in the same context are likely to be semantically related. However, co-occurrence matrices can become very large and computationally expensive for large vocabularies.
Prediction-Based Embeddings
3. Word2Vec (Skip-gram and Continuous Bag of Words)
Word2Vec is a popular technique for learning word embeddings, based on neural networks that learn the optimal word representations by training on a large dataset. Word2Vec embeddings are efficient to compute and can capture complex linguistic patterns.
Word2Vec is a group of neural architectures that has two main variants:
- Skip-gram: The model is trained to predict the context given a word. This technique is particularly useful when dealing with less frequent words, as it weighs the representation of each context-word pair, allowing it to capture a broader range of semantic relationships.
- Continuous Bag of Words (CBOW): The model predicts the target word from its context. CBOW tends to predict common words better, since it smooths over the entire context and is therefore faster to train.
4. FastText
FastText is a prediction-based embedding technique that extends Word2Vec by considering subword information. This allows FastText to generate better embeddings for rare and out-of-vocabulary words.
FastText takes into account the internal structure of words while learning representations; it represents each word as a bag of character n-grams in addition to the word itself. For example, the word “apple” would be represented by the n-grams: “ap”, “pp”, “pl”, “le”, if we chose n=2, and also the whole word “apple” as a separate feature.
This technique is especially effective for morphologically rich languages, where a single word can have many different forms, and also helps in understanding suffixes and prefixes. FastText can also be used to generate word embeddings for words that didn’t appear in the training data, making it robust for handling real-world text from diverse sources.
5. GloVe (Global Vectors for Word Representation)
Unlike Word2Vec, which considers local context windows, GloVe learns embeddings by leveraging global word-word co-occurrence statistics from the corpus.
GloVe is based on matrix factorization techniques on the word-context matrix. It first constructs a large matrix of (words × context) co-occurrence information, essentially counting how frequently a “context” word appears with a “target” word. Then, it uses least squares regression to factorize this matrix, yielding a lower-dimensional representation.
Unlike Word2Vec, which is a predictive model, GloVe is a count-based model. This method allows for capturing intricate patterns in the data, such as linear substructures of the word vector space, which can correspond to linguistic concepts like gender, verb tense, and pluralization.
Example Applications of Word Embeddings
Text Classification and Sentiment Analysis
Text classification involves assigning predefined categories to a given text, while sentiment analysis determines the sentiment expressed in that text. These tasks are crucial for understanding customer feedback, social media monitoring, and opinion mining to name a few.
Word embeddings are particularly effective in these applications as they convert text into numerical vectors that can be easily processed by machine learning algorithms. By capturing the semantic meaning of words, they enable the model to understand context, subtleties, and nuances in the text. This allows for more accurate and nuanced text classification and sentiment analysis.
For instance, by using word embeddings, a machine learning algorithm can differentiate between positive, negative, and neutral sentiments, or even detect sarcasm. The ability to accurately classify and understand sentiment in text data can provide valuable insights for businesses, policymakers, and researchers.
Machine Translation
Machine translation involves translating text from one language to another using machine learning algorithms. Word embeddings play a crucial role in this process by capturing the semantic relationships between words in different languages.
Word embeddings trained on bilingual text corpora can learn the mapping between the vector spaces of two languages. This allows for accurate translation of words and phrases, even when direct translations don’t exist.
This capability of word embeddings has revolutionized machine translation, enabling the development of powerful tools like Google Translate. It has also opened up new avenues for cross-lingual information retrieval and multilingual text analysis.
Information Retrieval and Search
Word embeddings are commonly used to improve search engines and information retrieval systems. Traditionally, these systems relied on keyword matching, which often fails to capture the semantic relationships between words, leading to less accurate search results.
Word embeddings, on the other hand, capture the semantic and syntactic relationships between words, enabling more accurate search results. For instance, if a user searches for ‘iPhone’, a traditional search engine might only return results that contain the exact keyword ‘iPhone’. A modern search engine powered by word embeddings, however, could also return results related to ‘Apple’, ‘smartphone’, or ‘iOS’, as it understands the semantic relationships between these words.
The capabilities offered by word embeddings are also having a major impact on recommendation systems and other information retrieval systems. It allows these systems to better understand user queries and deliver more relevant search results.
Named Entity Recognition
Named Entity Recognition (NER) is a sub-task of information extraction that seeks to locate and classify named entities in text, in categories like person names, organizations, locations, medical codes, quantities, and monetary values. This is crucial for tasks like information extraction, knowledge graph construction, and semantic search.
By mapping words to high-dimensional vectors, word embeddings capture the semantic and syntactic relationships between words, which can be leveraged for accurate named entity recognition.
For instance, a word embedding model can learn that the word ‘Apple’ in the context of ‘Apple Inc.’ refers to an organization, not a fruit. This understanding allows algorithms to more accurately identify and classify named entities in text.
Text Summarization
Text summarization is the process of creating a concise and coherent summary of a longer text document. It’s a challenging task due to the need to understand the main ideas in the text and generate a summary that accurately reflects those ideas. Word embeddings are an effective tool for text summarization as they capture the semantic meaning of words, enabling algorithms to understand the main ideas in the text.
By converting the words in a text document into numerical vectors, word embeddings enable the algorithm to identify key ideas and generate a summary that accurately reflects the content of the document. Word embeddings also enable the development of abstractive text summarization algorithms that can generate summaries with original text, rather than simply extracting key sentences from the text.
Challenges and Limitations of Word Embeddings
Despite their numerous benefits, word embeddings also have certain challenges and limitations.
Dealing with Polysemy
Polysemy, the phenomenon where a single word can have multiple meanings based on context, presents a significant challenge for word embeddings. For instance, the word ‘bank’ can refer to a financial institution or the edge of a river, depending on the context. Traditional word embeddings models assign a single vector to each word, which fails to capture this aspect of language.
Efforts have been made to develop context-sensitive word embeddings that can handle polysemy. These models generate different vectors for a word based on its context, allowing them to capture the different meanings of a word. However, these models are more complex and computationally intensive, which presents its own set of challenges.
Scalability Issues for Large Vocabularies
Even though embeddings are far more efficient than previous bag of words approaches, training a word embeddings model still requires a large amount of computational resources, especially for a corpus with a large vocabulary. This can make it difficult to train word embeddings models on large text corpora or for languages with many unique words.
Several solutions have been proposed to address this issue, such as subword embeddings, which break down words into smaller units. Another approach is to use dimensionality reduction techniques to reduce the size of the word embeddings without losing too much information.
Cultural and Gender Biases Embedded in Training Data
Finally, word embeddings can inherit and amplify the biases present in their training data. For instance, if the training data contains gender stereotypes, the trained word embeddings model can also exhibit these stereotypes. This can lead to biased results in applications like text classification, sentiment analysis, and machine translation.
Addressing this issue requires careful selection and preprocessing of training data to minimize biases. Another option is to use techniques that can debias word embeddings after training. However, this is a complex and ongoing challenge that requires further research and development.
Conclusion
In conclusion, word embeddings represent a significant advancement in the field of natural language processing, allowing machines to process text in a more human-like way by understanding the contextual nuances of language. These representations of words as vectors in a high-dimensional space have enabled breakthroughs in numerous applications, such as text classification, machine translation, and information retrieval.
Word embeddings address many of the limitations inherent in previous models by efficiently managing large vocabularies, reducing dimensionality, and enabling transfer learning. While challenges remain, such as handling polysemy, scalability, and embedded biases, word embedding techniques continue to evolve. They are likely to become even more important in a world increasingly driven by the analysis of vast amounts of textual data.