
AI coding assistants have ushered in a new era of software development. They enable developers to code faster, boosting productivity and the developer experience. According to GitHub, almost all developers (92%!) are actively using or experimenting with AI coding tools.
This is part of a series of articles about AI tools for developers
AI coding assistants
AI coding assistants are designed to take on a specific task, equipped with relevant contextual information, and then generate a solution based on the given input. The ‘context’ refers to the information provided to the AI model to help it understand and solve the task at hand. The ‘solution’ is the result produced by the model, such as a piece of code, an answer to a question, and the list goes on.
In this 3-part series (click here for part 2 and part 3), we will explore the various types of contextual information that can be beneficial for AI coding assistants.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a key concept in AI Assistants. This technique merges two models: a retrieval model and a generation model. The retrieval model is responsible for finding pertinent information from a database or knowledge source, such as context about code relevant to a specific programming task.
Once this information is retrieved, the generation model takes over, using the gathered data to generate text that answers or addresses the task at hand. Essentially, the AI assistant first locates the necessary information and then crafts a response or solution based on what it has found.
Take a look at this schematic (and simplified) representation of RAG:
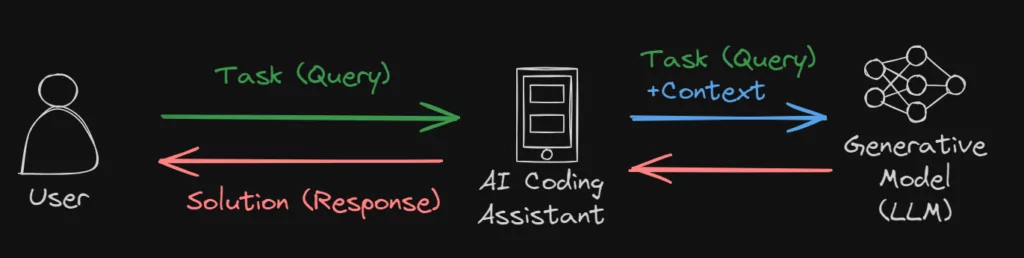
As you can see, the user sends the task (or query) to the AI assistant. The assistant then sends the task/query as well as relevant context to the generative model (for example, a Large Language Model, or LLM). Then, the model generates the solution (or answer) based on the task and context.
It’s important to remember that the quality of the generated solution is highly dependent on the context. Therefore, the retrieval part is crucial for the success of the AI Assistant.
Context for AI Coding Assistants
In this section, we’ll explore the different types of context that can be provided to the model and discuss the techniques used to acquire them.
Source code
Source code holds a lot of information that is critical to solving coding tasks. And in order to find relevant context, there are a number of techniques that we can use. The challenge here is finding the relevant parts in an imputed query.
For example, if a user is trying to implement a function that calculates the total price of a shopping cart, the LLM would need to find the relevant parts of the code that have to do with shopping carts and prices. If there is already a class representing a shopping cart with a way to enumerate its items, the LLM should know about it when generating the code suggestion.
In any RAG system, the initial step of building the knowledge base is crucial for efficient retrieval. We must first split the code into chunks, and then retrieve only the ones that are most relevant.
There are many ways to split the code into chunks:
Split by files
One method involves dividing each file into individual documentation and then employing a retrieval model to select the relevant files. The benefit here lies in its straightforward implementation. However, the disadvantage is that it’s not granular and finding the relevant parts of code within a file can be challenging.
Let’s go back to the scenario involving shopping carts and pricing functionality. Chances are, the relevant code is distributed across several files (perhaps one file for the handling of inventory, another for handling different currencies, and another for the payment itself), making it difficult to isolate the necessary parts without directly examining the code.
Split by line chunks
Another approach is to split the code into smaller segments, each consisting of a few lines, and then applying a “sliding window” technique across the code in order to analyze the sections sequentially. For instance, using a chunk size of 100 lines, we would first process the initial 100 lines of a file, then proceed to lines 101-200, and so on. Each chunk would be exclusively derived from a particular file and its length predefined (with, perhaps, the exception of the last chunk within a file, which may be smaller than the full length of the “window”).
This approach offers more detail, but it also presents challenges: a single chunk might contain unrelated code segments, complicating the retrieval process. Furthermore, the key logic we’re searching for could be distributed over multiple chunks, further complicating the extraction.
Relying on Static Analysis to split by code elements
Static analysis – the process of analyzing code without running it – allows us to dissect specific code files to identify and catalog different code elements within them. For example, parsing a Typescript file and extracting all the functions within it.
Then we can use this information to split the code into chunks of functions and use a retrieval model to retrieve the relevant functions. This approach is very granular and likely to retrieve only the relevant parts of the code.
However, not all code is written in a language that can be parsed using static analysis – and static analysis is not always accurate. Additionally, not all programming logic is contained within functions, which means significant portions of the code might go unanalyzed.
LangChain’s RAG over code tutorial is one example of this approach. Using supported languages (Python and Javascript) they:
- Keep top-level functions and classes together in a single document
- Insert remaining code into a separate document
- Retain metadata about where each split comes from
These documents are further split to align with the correct size for the retrieval model, and in the case of unsupported languages, they employ a simple sliding window approach.
Some thoughts on extracting context from source code
- Source code is an important resource when it comes to extracting context
- Extracting context is hard and worth exploring and in my opinion, a successful approach combines different techniques
- Don’t forget: source code is not the only resource we have at our disposal
And even with the greatest extraction techniques, we still face some issues:
- Source code will always miss important information that can’t be conveyed through code, such as business logic
- Code might contain errors or bugs, and we wouldn’t necessarily want to rely on it when generating code suggestions or answers to users
Conclusion
Source code is a crucial part of the context LLMs need to generate accurate responses when it comes to questions about code, but it’s only part of the equation. The infamous statement: “my code documents itself” shows its true colors in a situation like this. Yes, code can show what a function does, but code lacks other decisions, such as business or product logic, that went into coding something a specific way.
