
The pace at which AI is evolving is incredible to see, with new breakthroughs announced almost every other day. Most recently? Google’s Gemini 1.5 model – a dramatic improvement in terms of quality to the 1.0 Ultra model, while using less computing power.
However, what stands out the most from the announcement, at least from our perspective, is Gemini 1.5 Pro’s context size of 1M tokens. To put it in perspective, GPT-4 Turbo’s window is 128k tokens.
The introduction of such groundbreaking technologies can quickly lead to hasty conclusions. One of them that I’ve seen recently is that RAG is dead/going to die. As Donato Riccio put it: “My prediction is that in a year or two RAG as we know it today will no longer be needed, as LLMs scale their context to unlimited sizes.”
I disagree.
What is RAG? (If you’re familiar, skip ahead)
A RAG system retrieves relevant context for a task and then provides the LLM with this context alongside the query. I’ve extensively covered this topic in a separate article, which you can read here contextualizing AI source code.
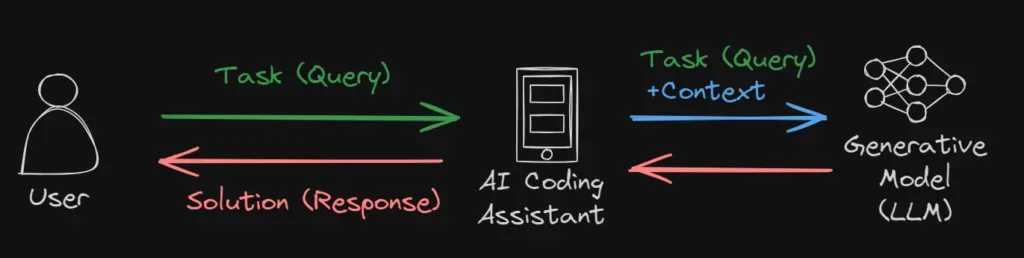
In the case of coding assistants (/ask Swimm, for example), when a user asks a question like “How do I add a new plugin to the system?”, the LLM’s context might include examples of different plugins and perhaps a guide on adding a new plugin.
The necessity of RAG
Without information about the specific codebase, an LLM cannot possibly know the answer. This raises an intriguing question: why not just send the entire codebase along with the query?
There are a few reasons:
- Limited context windows: With GPT-4 Turbo, up to 128k tokens can be sent, while other GPT-4 versions support 8k or 32k tokens. If your codebase exceeds these limits, you can’t fully send it to the LLM.
- Needle in a haystack: LLMs need to discern what’s relevant to the query. Sending an entire codebase is like asking someone to find a specific answer in an entire book rather than a specific paragraph. It’s been proven that LLMs perform worse when given too much context. Pinecone reviewed two papers on the topic, and the results were consistent: LLMs perform much worse when given too much context.
- Speed: Sending an entire codebase to an LLM is slow. It goes without saying that it’s much faster to send a query and the relevant context.
- Cost: Sending queries to LLMs is costly, with the cost increasing linearly with the number of tokens. So from a business standpoint, it just doesn’t make sense – sending concise queries is more viable.
So what’s all the fuss surrounding Gemini about?
Google’s new model shows impressive capabilities regarding the Needle-in-a-Haystack problem, demonstrated specifically about codebases.
Check out this video where Google showcases how they can take up to 1M tokens of context AND still provide relevant answers.
In my opinion, this is super impressive and would lead us to believe that points 1 and 2 (as described above) are solved, right?
Let’s take a closer look:
Breaking down the claim
Revisiting the four reasons RAG is necessary:
- Limited context windows: This challenge appears to be resolved. The technical constraints are diminishing, and there’s every reason to believe that capacities like 1M (or even 10M, as Google’s research suggests) will continue to expand.
- Needle in a haystack: This one is tricky. While Google’s model can provide relevant answers within a 1M token context for straightforward queries, it falls short in addressing more nuanced engineering queries that require an in-depth understanding of a codebase, which is not easily gleaned from the code itself.
- Speed: This hasn’t been solved. It’s still much faster to send a query with accompanying context than sending the entire codebase.
- Cost: Also not solved. It’s still much cheaper to send a query with accompanying context than sending the entire codebase.
Conclusion
As things change so fast in the AI world, it’s hard to predict the future with confidence, but it seems like RAG is still relevant. It’s not clear that the Needle-in-a-Haystack problem is solved, and it’s clear that the speed and cost problems are not solved. So for real-life systems, RAG is still relevant, and will probably remain relevant in the near future.
While Gemini 1.5 Pro is indeed revolutionary, it does not negate the necessity for RAG, especially for coding-related tasks. It solves the issue of limited context windows but doesn’t address the Needle-in-a-Haystack challenge, nor does it tackle speed and cost concerns.
