Word2Vec is a group of machine learning architectures that can find words with similar contexts and group them together. When we say ‘context’, it refers to the group of words that surrounds a given word in a sentence or a document. This grouping, also known as word embeddings, results in a cluster of vectors that have similar meanings. The vectors representing words with similar meanings are positioned close to each other in this high-dimensional space.
Technically, Word2Vec is a two-layer neural network that processes text by taking in batches of raw textual data, processing them and producing a vector space of several hundred dimensions. Each unique word in the data is assigned a corresponding vector in the space. The positioning of these vectors in the space is determined by the words’ semantic meanings and proximity to other words.
Word2Vec has become a core component of many higher-level algorithms in the world of natural language processing (NLP). It’s one of the enablers of the substantial advancements we’ve seen in language-based machine learning applications, including machine translation, speech recognition, and AI chatbots.
This is part of a series of articles about large language models.
Word2Vec Architecture
The Word2Vec model can be implemented using two architectural designs: the Continuous Bag of Words (CBOW) Model and the Continuous Skip-Gram Model. Both models aim to reduce the dimensionality of the data and create dense word vectors, but they approach the problem differently.
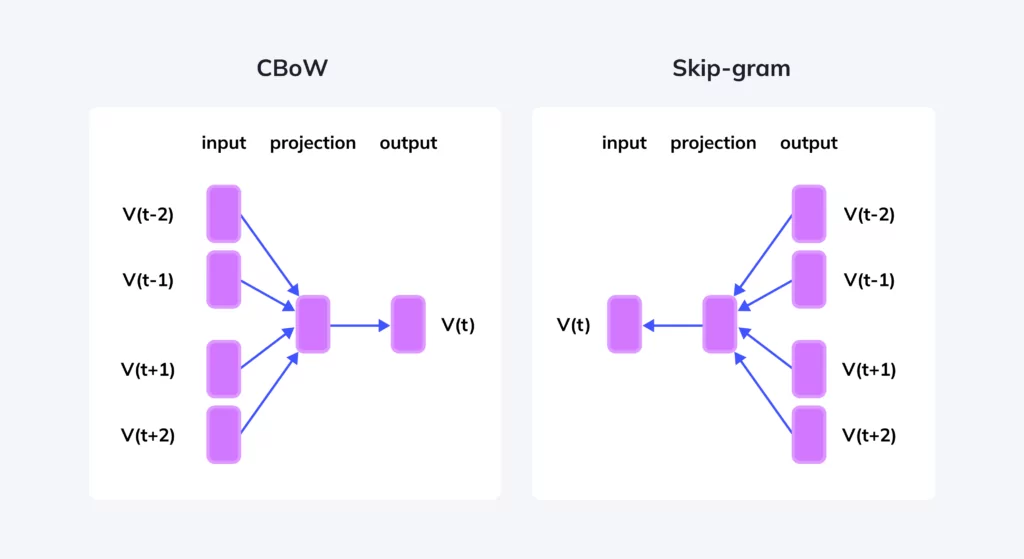
CBOW (Continuous Bag of Words) Model
The CBOW model predicts the target word from its surrounding context words. In other words, it uses the surrounding words to predict the word in the middle. This model takes all the context words, aggregates them, and uses the resultant vector to predict the target word.
For example, in the sentence “The cat sat on the mat,” if we use “cat” as our target word, the CBOW model will take “The”, “sat”, “on”, “the”, “mat” as context and predict the word “cat”. This model is beneficial when we have a small dataset, and it’s faster than the Skip-Gram model.
Continuous Skip-Gram Model
The Skip-Gram model predicts the surrounding context words from a target word. In other words, it uses a single word to predict its surrounding context. For example, if we again take the sentence “The cat sat on the mat,” the Skip-Gram model will take “cat” as the input and predict “The”, “sat”, “on”, “the”, “mat”.
This model works well with a large dataset and with rare words. It’s computationally more expensive than the CBOW model due to its task of predicting multiple context words. However, it provides several advantages, including an improved ability to capture semantic relationships, handle rare words, and be flexible to linguistic context.
Training Word2Vec Embeddings
Here are the general steps involved in training Word2Vec embeddings from a text dataset.
Initialization of vectors
Each word in the corpus is initially represented as a high-dimensional vector with random values. These vectors serve as the starting point for the training process.
The dimension of these vectors is typically around 100-300, and sometimes up to a thousand, depending on the size of the corpus and the specific requirements of the task at hand. The random initialization helps in breaking symmetry and ensures that the model learns something useful as it starts training.
As the training progresses, these vectors are updated based on the objective function of the Word2Vec model, which is designed to position vectors of words appearing in similar contexts closer to each other in the vector space.
Optimization Techniques and Backpropagation
Once we have the initial word vectors, the next step involves optimizing these vectors to better capture the linguistic contexts of words. This is done using various optimization techniques, primarily gradient descent and its variants.
The main idea is to iteratively adjust the word vectors so that the model’s predictions align more closely with the actual context words. The measure of alignment is given by the objective function, and the adjustment is carried out through a process known as backpropagation.
Backpropagation is a method used in neural networks to calculate the gradient of the loss function with respect to the weights of the network. In the context of Word2Vec, backpropagation adjusts the word vectors based on the errors in predicting context words. Through successive iterations, the model becomes increasingly accurate in its predictions, leading to optimized word vectors.
Importance of Window Size
Another critical aspect of training Word2Vec embeddings is the choice of window size. The window size is like a sliding window that passes over the text and determines which words are analyzed in context of a target word. Words within the window are considered as context words, while those outside are ignored.
The choice of window size impacts the quality of learned word vectors. A smaller window size results in learning more about the word’s syntactic roles, while a larger window size helps the model understand the broader semantic context.
However, there’s a trade-off to consider. A larger window size increases the computational complexity as more context words have to be processed for each target word. Therefore, the choice of window size should be done carefully, taking into account both the computational resources and the specific requirements of the task.
Negative Sampling and Subsampling of Frequent Words
Negative sampling addresses the issue of computational efficiency by updating only a small percentage of the model’s weights at each step rather than all of them. This is done by sampling a small number of “negative” words (words not in the context) to update for each target word.
On the other hand, subsampling of frequent words helps in improving the quality of word vectors. The basic idea is to reduce the impact of high-frequency words in the training process as they often carry less meaningful information compared to rare words.
By randomly discarding some instances of frequent words, the model is forced to focus more on the rare words, leading to more balanced and meaningful word vectors.
Word2Vec Extensions and Variants
Word2Vec is used extensively by the data science community, and several variants have been developed for different use cases. Here are some of the more important ones:
Doc2Vec
Doc2Vec is an extension of Word2Vec that allows the model to understand phrases or entire documents, rather than just individual words. Like Word2Vec, Doc2Vec represents documents as vectors, but with an added layer of complexity. It assigns a unique identifier to each document and uses it to adjust the word vectors.
The document identifier and the word vectors are trained together, enabling the model to predict the next word in a sentence. This gives us a vector representation of the entire document, which can be used for document comparison, document clustering, and numerous other tasks.
Doc2Vec is particularly useful in applications such as information retrieval, sentiment analysis, and document recommendation systems. For example, in sentiment analysis, Doc2Vec can capture the overall sentiment of a document, making it more effective than Word2Vec, which only understands the sentiments of individual words.
Top2Vec
Top2Vec is a newer algorithm that extends the concepts of Word2Vec and Doc2Vec. It is designed to automatically detect topics in text data. Top2Vec works by creating joint document- and word-vectors. It uses these vectors to find dense areas of similar documents in the vector space. These dense areas represent topics, and the words closest to the center of these areas are the most descriptive words for the topics.
One of the main advantages of Top2Vec is that it doesn’t require any prior knowledge of the number of topics in the text data. It automatically determines the number of topics. This makes it particularly useful for exploratory data analysis, where you don’t have prior knowledge about the data.
BioVectors
BioVectors is another variant of Word2Vec, specifically designed for biomedical texts. Bioinformatics is a field that has to deal with a large amount of unstructured text data. BioVectors helps in this regard by converting this unstructured text into structured numeric vectors, which can then be used for further analysis.
BioVectors trains word vectors using Word2Vec, but with a crucial difference. It uses domain-specific corpora, like PubMed and PMC texts. This allows BioVectors to capture biomedical semantics accurately. BioVectors can be used for tasks like disease gene discovery, drug repurposing, and predicting protein interactions.
Conclusion
In conclusion, Word2Vec offers a powerful method for machines to understand human language by transforming words into numeric vectors. The efficacy of Word2Vec stems from its ability to detect semantic and syntactic similarities among words, using architectures like CBOW and Skip-Gram, each suited to different data scales and outcomes.
Training these models requires careful selection of hyperparameters like window size and strategies such as negative sampling and subsampling to balance computational efficiency with the richness of word representations.
Word2Vec is adaptable to many different scenarios, as can be seen in multiple extensions developed around the core model. We covered Doc2Vec, which handles larger text units, Top2Vec, which facilitates unsupervised topic discovery, and BioVectors, which creates word embeddings for the specialized field of biomedicine.
Word2Vec has improved the ability of machines to grasp language, enhancing many machine learning applications, to become a cornerstone in the field of natural language processing.
Get started with Swimm today!