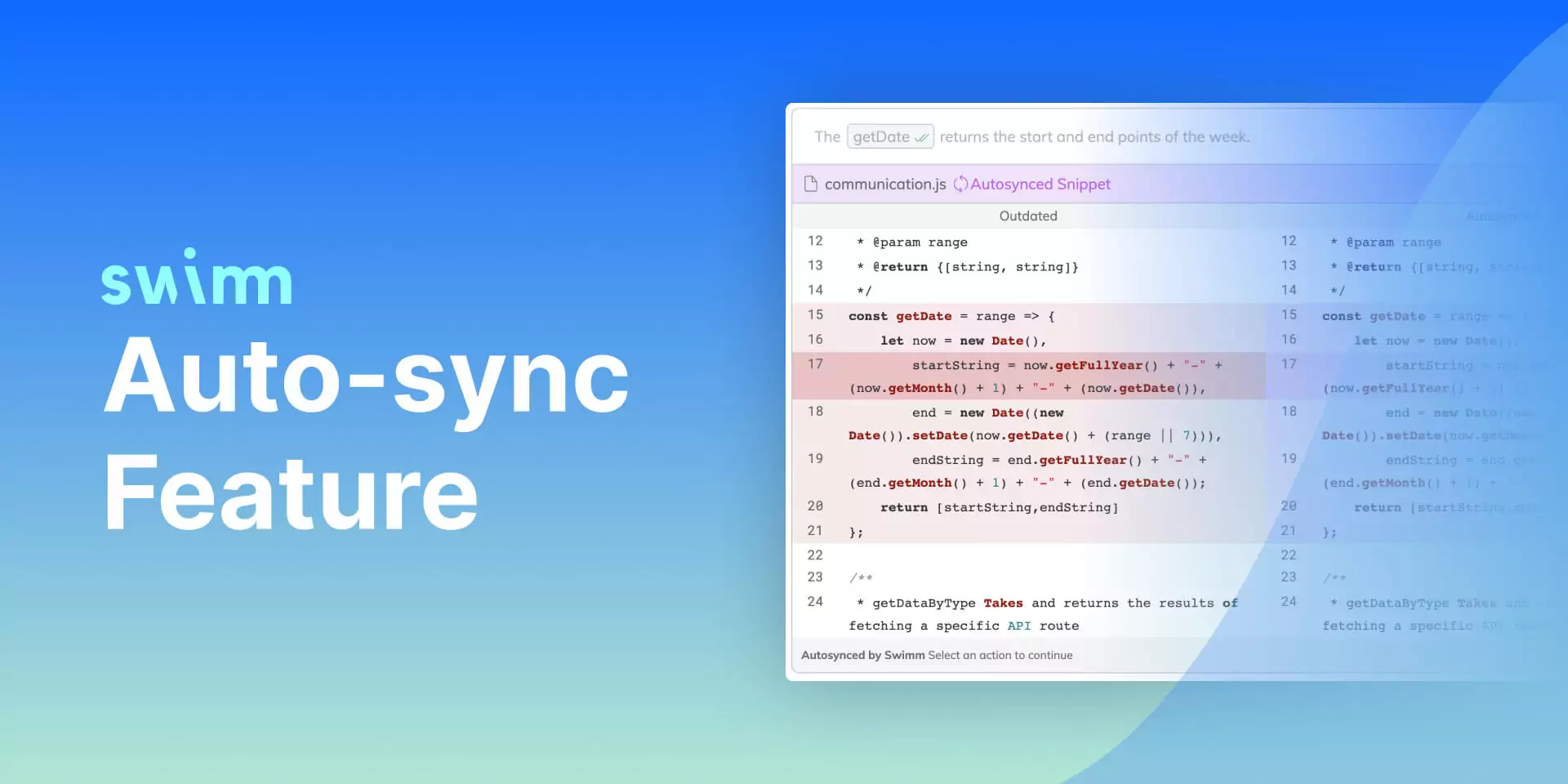
Swimm has lots of really amazing features and I really enjoy calls where I can see people’s reactions as I show them things. But perhaps the biggest looks of awe and admiration come when they see how Swimm’s patented Auto-sync features saves real, calculable time.
From a technical brief standpoint, it’s important to remember that the context of your code snippets as well as the nature of the change can impact how Auto-sync makes decisions to proceed, or ask its humans for help.
A high-level look at Auto-sync
The challenge: create something that is completely language-agnostic that can automatically keep code snippets up-to-date through most routine code changes.
While we go about meeting different kinds of needs with different programming languages, we think mostly about what sets languages apart from each other. You use Golang for [x] and C++ for [y], and maybe Lua or just Java if you’re writing a game mod. Swimm’s focus is what these languages have in common when it comes to the footprint that common changes create.
When we take something simple like int i = 0; and change it to something like int i[MAX_NUMS] = {}, we need to look up some language references (no pun intended) in our brains to process what just changed.
So, naturally, when someone reasonably well-learned in C observes Swimm automatically syncing that exact change, they immediately begin picking apart how Swimm knew that was safe, which sort of begs how it knew it was a good candidate to sync.
Swimm has no knowledge of types, syntactic sugar flavors, intermediate compiler output (where code gets broken down to assembly and is used as part of the documentation) or other things that we engineers spent lots of time learning.
Swimm has us, so it doesn’t need to know that stuff.
What Swimm needs to do is examine every other conceivable piece of information available in a change (including previous history) to determine the closest narrative to what happened in the code based on many small sources of signal surrounding the change.
With Auto-sync, what happens to the code?
We can’t give a completely exhaustive prediction of how Auto-sync behaves with any given change because there are just too many variables at play. Here, we’re focusing more on how to anticipate and work with it in your own workflow, which is what matters the most for you to get the full value from it.
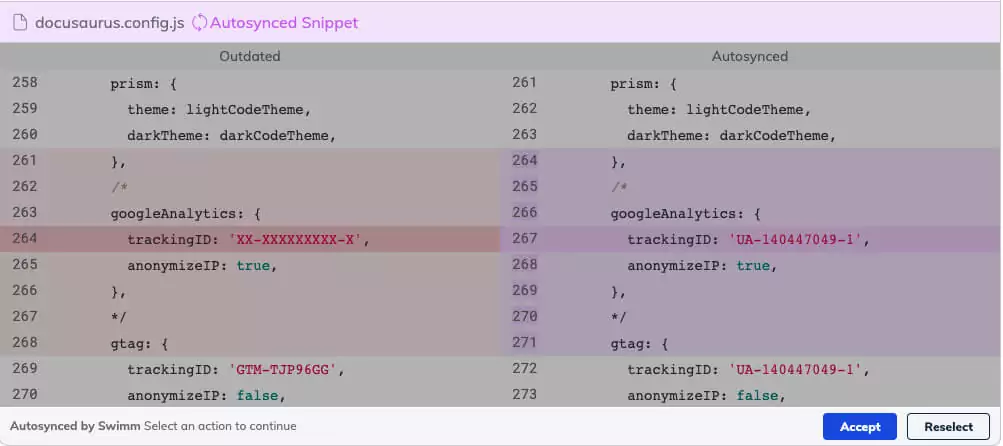
The decision-making tree on what’s likely sync-able and what needs human help will most often involve finding answers to the following questions:
- Did the code just move? If it’s still there and exactly the way we remember it, and there’s nothing else affecting it, just Auto-sync the snippet. In this case, as well as other very simple cases, we actually don’t notify the user at all and would mark the snippet as verified.
- Is the change trivial in nature? Triviality can be very subjective, of course, but what we’re trying to determine very quickly is if a variable was renamed or removed without any other functional impact to the code.
- What’s going on with any other nearby bits and tokens that we’re tracking?
- Have any smart tokens or paths that Swimm has been taught to monitor changed?
- Did the code vanish entirely? If so, it took its secrets with it, because we can’t document a negative. Good thing we have humans to help!
There are more, many more small pieces of signal that can be analyzed to produce a likely understanding of if the change should just be reflected automatically (Auto-synced) or if we need to have someone review it. And as Swimm is used with more and more languages, we’ll have an even better understanding of its limits.
Currently, we have yet to find any limits to this approach, and that’s a great place to start talking about how Swimm knows to ask its humans for help.
Auto-sync knows when not to sync
If you were thinking “well that certainly sounds like the change passes a score threshold and syncs if that happens, right?”
That isn’t incorrect, and if you’re satisfied with that explanation, by all means jump down to the other parts of this post. Just remember the feature itself is still under heavy development, and a lot of behavior depends on your style of documentation.
What happens when Auto-sync does not have enough information to sync
All bits of signal (line markers, line numbers, token references, size of the change, history of the file in version control, and many other things) come together to form a sort of histogram of the code snippet and change to evaluate, and different characteristics have a higher priority in the decision making process than others, if they’re present.
If you wondered why Swimm won’t work with ‘shallow’ clones of repositories, this is why: we need to be able to analyze the full history.
As we iterate over every possible data point about the change and examine the history of the code keeping track of all of these different-sized pieces of signal, Swimm’s Auto-sync feature understands when something cannot be Auto-synced – at which point we leave a task for someone on your team to reselect the snippet. We’d rather ask you to reselect a snippet than offer a strange suggestion. But at the same time, we really want you to see Swimm’s Auto-sync (IMHO, one of our best features) working for you constantly and saving you time, not missing what looks like obvious opportunities to do so.
It’s a balance, to say the least.
How does this transcend to smart text and smart paths?
For 1:1 replacements like tracking a variable named ‘foo’ and later renaming it to ‘foobar’ not very much ‘thinking’ is required. If the token or path is completely removed, then Auto-sync will let you know and ask you to select something else or remove the reference entirely. This is also what happens if paths or file names change, provided that you use Git to change or remove them.
Auto-sync increases speed and removes friction from your dev loop
Swimm makes contributing to new code faster for everyone, and Swimm relies considerably on the DVCS (right now Git exclusively, but we plan to support more) as storage, and interacts with it that way.
Do you ever think about how cool it’s going to be when the first commit in a repo turns a whole century old? The people on our R&D team think about stuff like that all the time.
All of these checks need to be able to be completed in a length of time that doesn’t cause Swimm to clog up builds on contentious CI servers. For those that can’t use CI/CD in their workflows yet and need to run verification checks locally prior to committing, we absolutely can’t slow them down. Additionally, Auto-sync tries very hard to not impose a workflow on you that doesn’t work for you – it’s completely optional to block merging pull requests that have outstanding issues. Blocking tends to make sure things get fixed quickly, but we leave that completely up to you.
Code hosting services also have their own characteristics. We won’t compare them because they’re all great in many different ways, but some are just considerably faster than others when it comes to integrations that happen on triggers.
Auto-sync and Git
Auto-sync knows Git very well, to say the least. Right now we’re just talking about Git, but eventually supporting other DVCS utilities like Mercurial requires our R&D team to know these tools (and popular extensions that affect their performance) almost as thoroughly as the people that wrote and designed them.
This ties to performance just as much as it does safety and security; we can’t leave any help that Git can give us on the table when it comes to delivering Auto-sync with the kind of speed and consistency our customers need.
As Git (and, eventually, others) become more performant, Swimm will continue to scale the performance ladder too. This is way more than just watching out for breaking changes; this is keeping up with what’s going on and looking ahead to what that might mean for us in terms of additional performance, as well as making sure we don’t go slower due to new changes or behavior.
Bottom line
As Swimm gains increasing adoption and popularity in many different kinds of workflows, Auto-sync will remain front and center and we’ll do our best to share more as we improve it through frequent iterations.
What’s most important to remember right now is that it works, and if you’re thinking about making a change and your instinct says “That should just get Auto-synced,” you’re very likely correct. Note, we’re making great strides forward in more granular control over reviewing suggestions, so that Swimm can bug you (mostly) for things that you’d appreciate seeing suggestions for and reviewing.
Learn more about Swimm or sign up for a demo and see Auto-sync in action for yourself.
